Python爬虫:爬取小说并存储到数据库
admin
2023-05-23 22:43:09
0次
爬取小说网站的小说,并保存到数据库
第一步:先获取小说内容
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib2,re
domain = 'http://www.quanshu.net'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
def getTypeList(pn=1): #获取分类列表的函数
req = urllib2.Request('http://www.quanshu.net/map/%s.html' % pn) #实例将要请求的对象
req.headers = headers #替换所有头信息
#req.add_header() #添加单个头信息
res = urllib2.urlopen(req) #开始请求
html = res.read().decode('gbk') #decode解码,解码成Unicode
reg = r'(.*?)'
reg = re.compile(reg) #增加匹配效率 正则匹配返回的类型为List
return re.findall(reg,html)
def getNovelList(url): #获取章节列表函数
req = urllib2.Request(domain + url)
req.headers = headers
res = urllib2.urlopen(req)
html = res.read().decode('gbk')
reg = r'(.*?) style6\(\)'
return re.findall(reg,html)[0]
if __name__ == '__main__':
for type in range(1,10):
for url,title in getTypeList(type):
for zurl,ztitle in getNovelList(url):
print u'正则爬取----%s' %ztitle
content = getNovelContent(url.replace('index.html',zurl))
print content
break
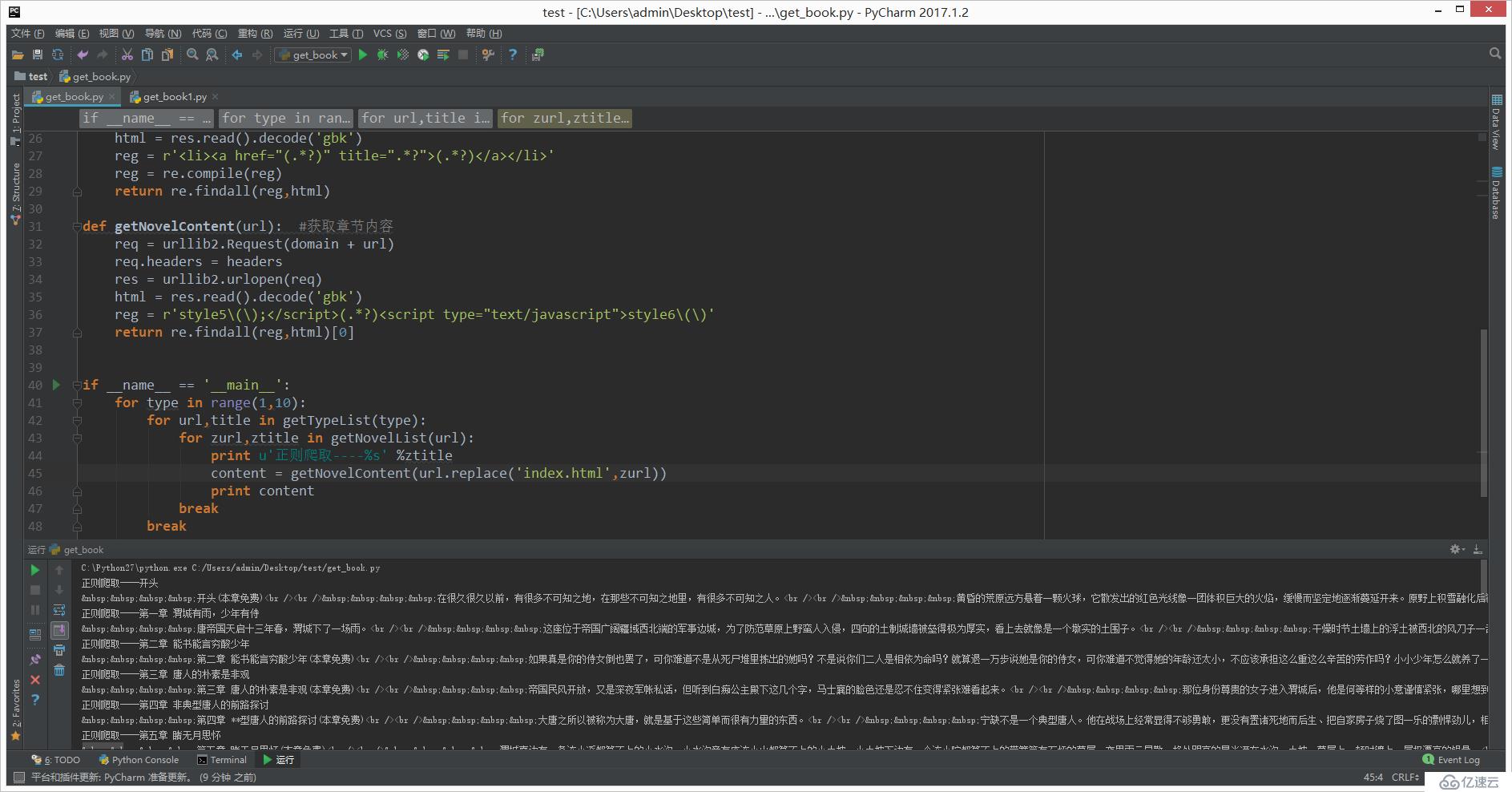
break 执行后结果如下:
第二步:存储到数据库
1、设计数据库
1.1 新建库:novel
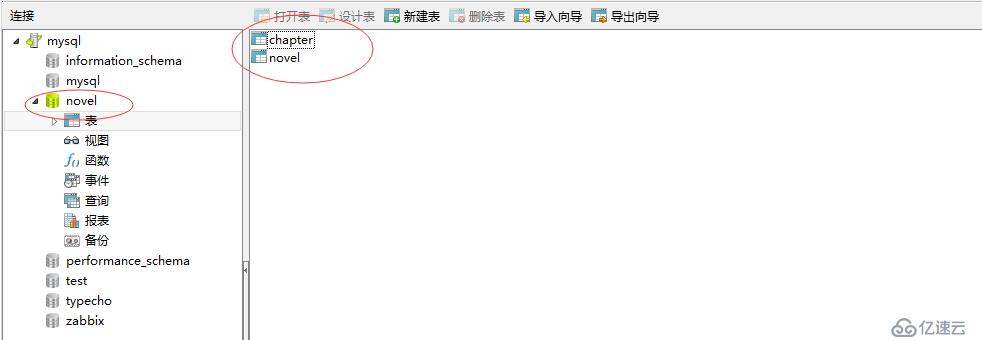
1.2 设计表:novel
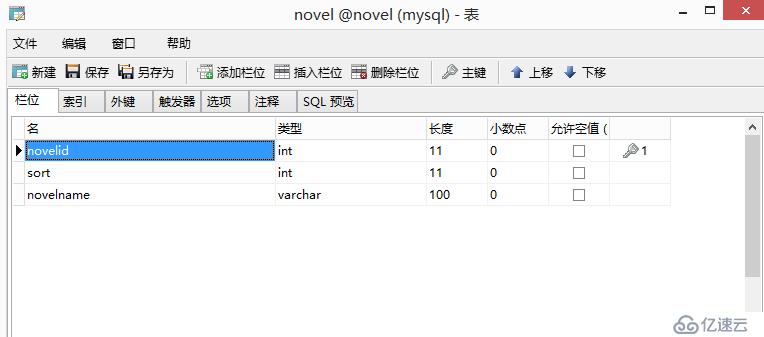
1.3 设计表:chapter
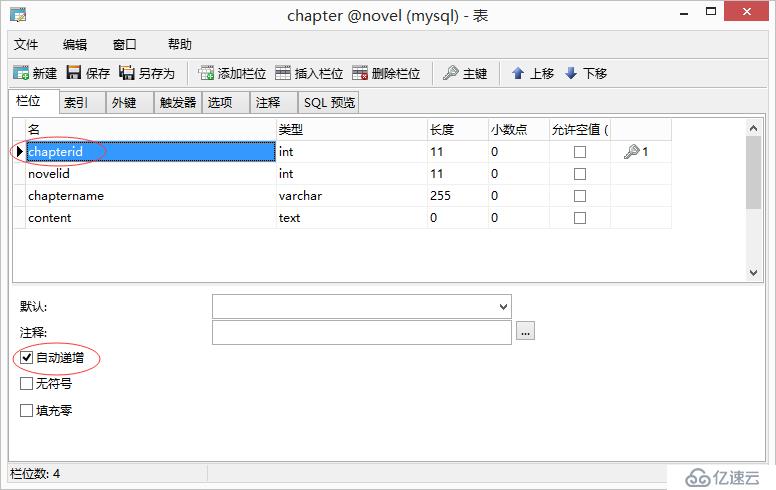
并设置外键

2、编写脚本
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib2,re
import MySQLdb
class Sql(object):
conn = MySQLdb.connect(host='192.168.19.213',port=3306,user='root',passwd='Admin123',db='novel',charset='utf8')
def addnovels(self,sort,novelname):
cur = self.conn.cursor()
cur.execute("insert into novel(sort,novelname) values(%s , '%s')" %(sort,novelname))
lastrowid = cur.lastrowid
cur.close()
self.conn.commit()
return lastrowid
def addchapters(self,novelid,chaptername,content):
cur = self.conn.cursor()
cur.execute("insert into chapter(novelid,chaptername,content) values(%s , '%s' ,'%s')" %(novelid,chaptername,content))
cur.close()
self.conn.commit()
domain = 'http://www.quanshu.net'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
def getTypeList(pn=1): #获取分类列表的函数
req = urllib2.Request('http://www.quanshu.net/map/%s.html' % pn) #实例将要请求的对象
req.headers = headers #替换所有头信息
#req.add_header() #添加单个头信息
res = urllib2.urlopen(req) #开始请求
html = res.read().decode('gbk') #decode解码,解码成Unicode
reg = r'(.*?)'
reg = re.compile(reg) #增加匹配效率 正则匹配返回的类型为List
return re.findall(reg,html)
def getNovelList(url): #获取章节列表函数
req = urllib2.Request(domain + url)
req.headers = headers
res = urllib2.urlopen(req)
html = res.read().decode('gbk')
reg = r'(.*?) style6\(\)'
return re.findall(reg,html)[0]
mysql = Sql()
if __name__ == '__main__':
for sort in range(1,10):
for url,title in getTypeList(sort):
lastrowid = mysql.addnovels(sort, title)
for zurl,ztitle in getNovelList(url):
print u'正则爬取----%s' %ztitle
content = getNovelContent(url.replace('index.html',zurl))
print u'正在存储----%s' %ztitle
mysql.addchapters(lastrowid,ztitle,content) 3、执行脚本
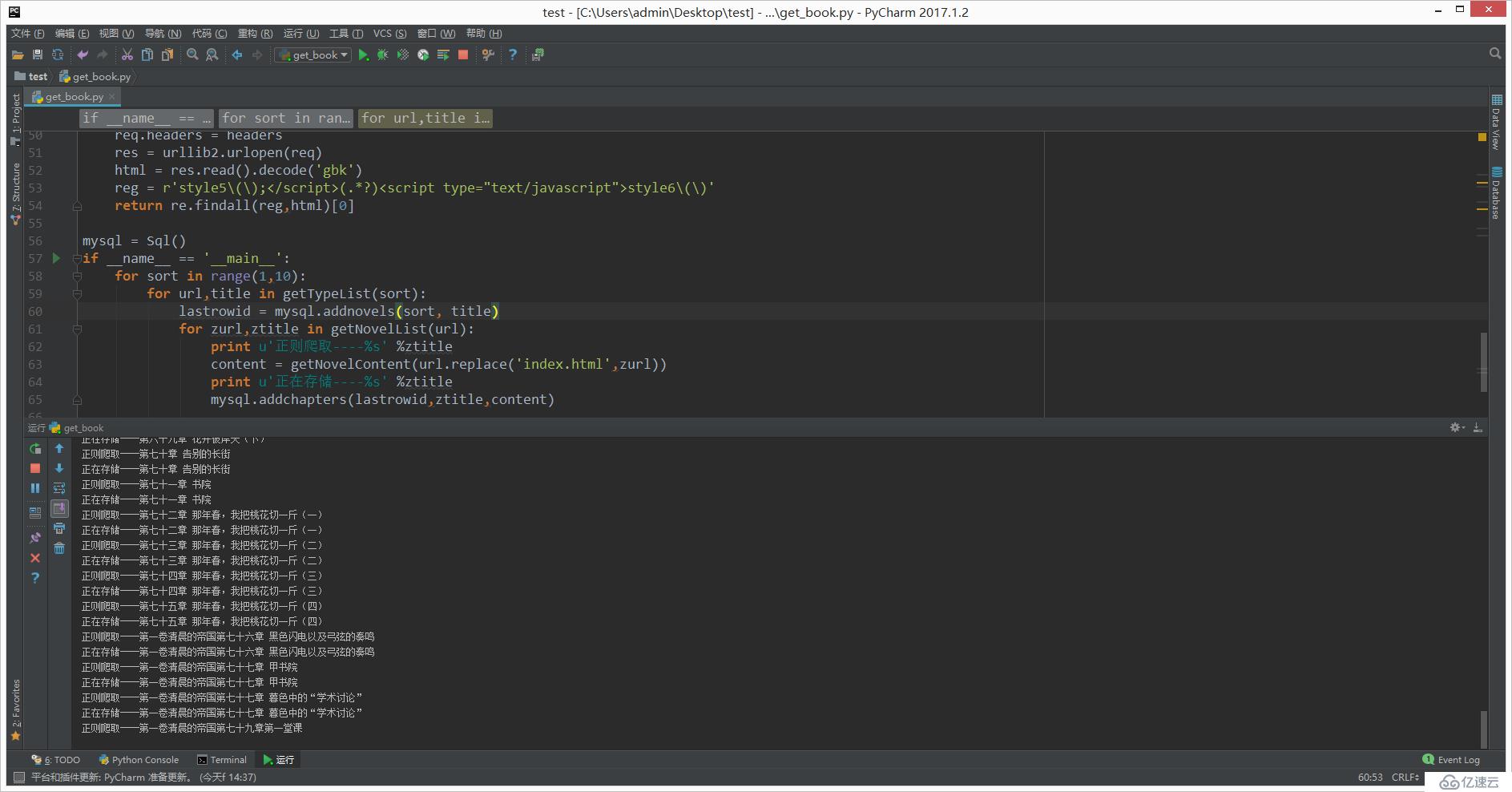
4、查看数据库
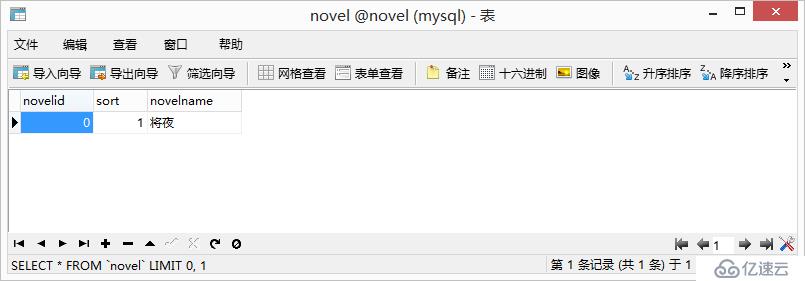
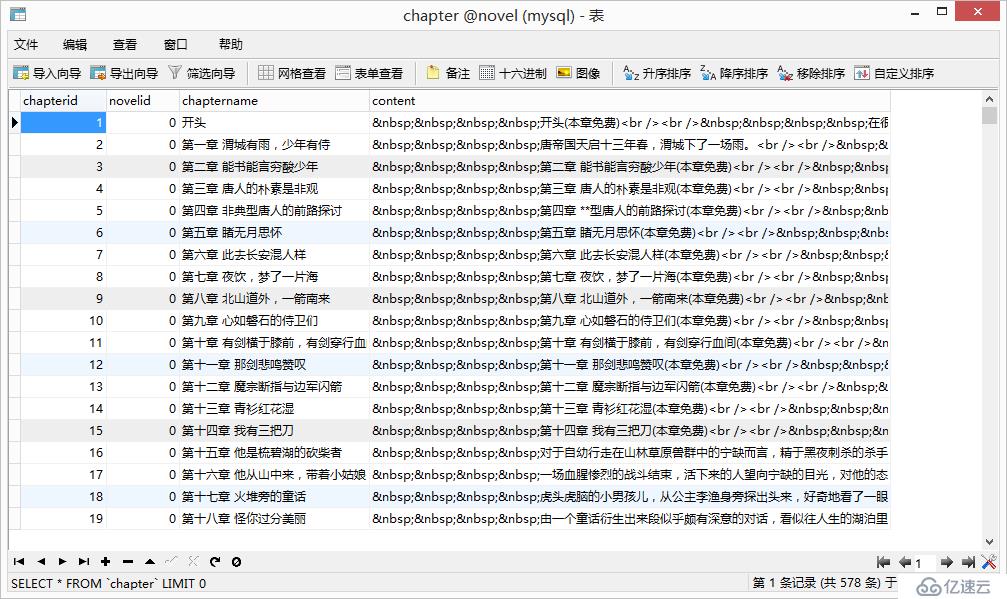
可以看到已经存储成功了。
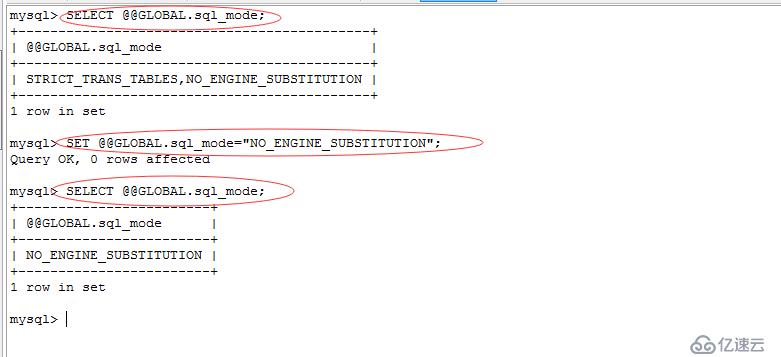
报错:
_mysql_exceptions.OperationalError: (1364, "Field 'novelid' doesn't have a default value")
解决:执行sql语句
SELECT @@GLOBAL.sql_mode;
SET @@GLOBAL.sql_mode="NO_ENGINE_SUBSTITUTION";
报错参考:http://blog.sina.com.cn/s/blog_6d2b3e4901011j9w.html
上一篇:Oracle进阶学习之创建数据库
相关内容
热门资讯
德瑞斯电子取得新型散热风扇专利...
国家知识产权局信息显示,深圳市德瑞斯电子科技有限公司取得一项名为“一种新型散热风扇”的专利,授权公告...
新兴技术及应用产业日报(05....
公司动态 中国移动段晓东:6G智能体通信——智能经济发展新范式 中国移动研究院副院长段晓东在...
2026年618购机指南:50...
随着618购物节的临近,许多消费者都在寻找一款预算在5000元左右,既能满足日常高强度拍照需求,又无...
体育博物馆如何在互联网时代维持...
上海体育博物馆正在利用更多科技与智能,让游客能够沉浸式逛展。 博物馆如何在当今人工智能盛行的互联网时...
万斯大型失忆现场:呼吁投票反对...
美国副总统JD・万斯近日深陷网络群嘲。他呼吁支持者“投票反对华盛顿疯狂的领导层”,似乎忘了如今是谁在...
原创 在...
NASA的气候模拟研究显示:40 亿年前,太阳刚形成不久,亮度只有现在的70%,整个太阳系比现在凉爽...
24岁演员,骑机车意外离世
近日,24岁短剧男演员黄子仟被曝离世,好友任九晗发文悼念,称从没想过再次见面,是看着你从冷柜里被抬出...
800元免费领,让养老院“头疼...
“没想到,都快5月了,在我们这么大的社区,我是第一个申领养老消费券的人。”4月下旬,在90多岁父亲出...
方太燃气灶打不上火是什么原因?
可能是燃气灶 没有开燃气阀,有的时候是忘记开燃气阀门了;可能是燃气灶喷嘴堵塞,影响喷嘴点燃燃气;还可...
带熄火保护的燃气灶不出气怎么办
开启开关出现了故障,如果是带熄火保护的燃气灶由于使用年限过长,导致出现问题,则意味着无法正常进行使用...