以我的亲身体验,谈谈如何正确理解“养虾”
【文/观察者网专栏作者 陈经】
2026年1月,一个叫Clawdbot的个人AI助理火了,是独立开发者Peter Steinberger(彼得·施泰因伯格)2025年11月24日创建的。因为名字与Anthropic的Claude大模型接近,作者将其改名为Moltbot,并建立了非常活跃的开发者社区Moltbook。3月10日,收购爱好者扎克伯格将Moltbook社区纳入旗下,而Steinberger早在2月就被OpenAI挖走。
笔者第一时间就关注了事件,并写文评论了Moltbot与“一人公司”(发在2月6日的环球时报),介绍AI与中国制造业分别从软硬两方面提供便捷服务,对于个人创业很有意义。没想到的是,3月时多家中国互联网巨头与大模型公司都参与进来了,一些地方政府都出资激励个人开发者,热度与2023年初的ChatGPT、2025年初的DeepSeek可以相比。
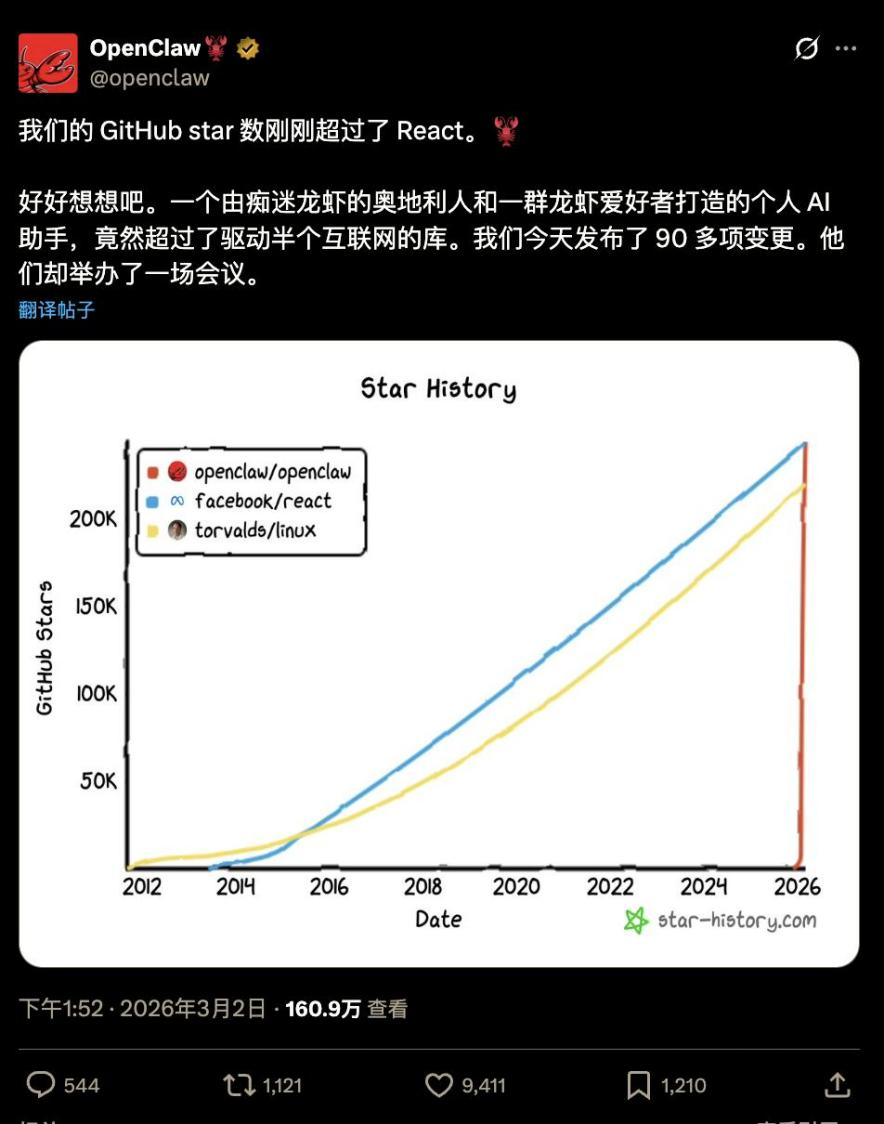
Moltbot于2026年1月30日正式更名为OpenClaw,并于2月24日超过有30年历史的LINUX、3月2日超过React,成为开源社区GitHub史上星标最多的软件项目。近乎垂直的增长曲线成为开源软件历史上的奇观。
OpenClaw作为开源项目,使用有一定门槛,中国爱好者有能力自行下载安装的不多。KimiClaw是中国大模型公司最早推出的OpenClaw云服务,不是装在个人电脑上,而是在云上开LINUX虚拟机,安装方便,春节前推出了试点。后面MaxClaw、DuClaw等各类云Claw产品越来越多,阿里云、腾讯云、华为云、火山引擎、京东云、移动云、天翼云都推出了“一键部署”解决方案。还有AutoClaw、QClaw这些作为Windows、MacOS的程序安装包,装在用户个人电脑上的。
这些“Claw”服务的推出,标志着中国AI厂商正在争夺OpenClaw生态主导权,与2025年2-3月各厂商纷纷部署接入DeepSeek类似。
一. 探索OpenClaw的多种方式
KimiClaw于2月18日正式上线,笔者立刻交了199月费,兴冲冲地“一键安装”。几天都连不上服务器,应该是春节没上班。2月22日属于笔者的KimiClaw终于活了,按套路设置连上飞书以后,可以顺畅使用了。笔者的兴趣是了解OpenClaw的架构与原理,这方面有一些心得,对于其优势与缺陷的根源也较为清楚。
本文对OpenClaw进行原理性技术解释,会普及一些基础概念。更重要的是祛魅,正确认识这只热度空前的“龙虾”,不神化其功能,了解其巨大的潜力与本质缺陷。
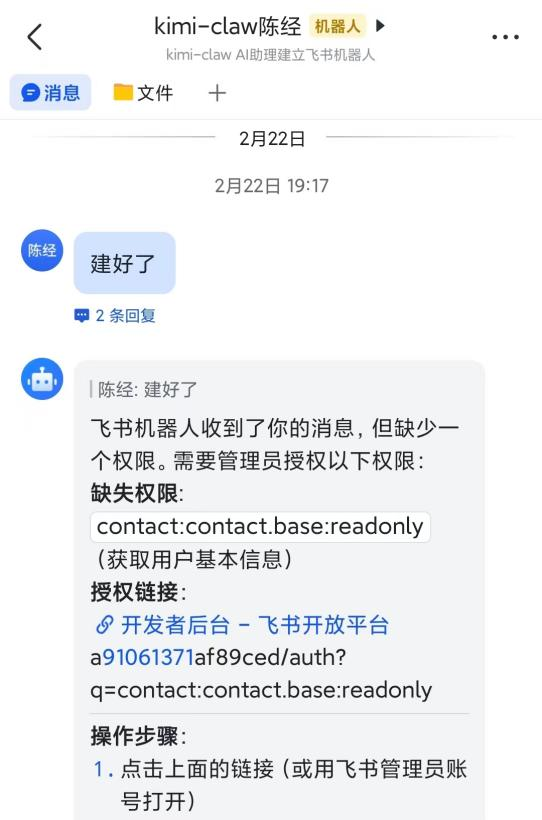
中国已经接上OpenClaw的用户,一般和它有两个交互渠道。一个是飞书等手机即时通讯APP,上面加了Claw机器人,聊天下达指令、接收文件,相信微信不久也会大规模接入。其原理是,飞书会提供API接入办法,OpenClaw有了API权限以后,就可以和飞书通信,接收指令、返回结果。这也是Steinberger开发OpenClaw的初衷,想用手机即时通讯APP连接自己的电脑,远程查看结果、指挥干活。目前这也是和OpenClaw最主要的沟通方式。
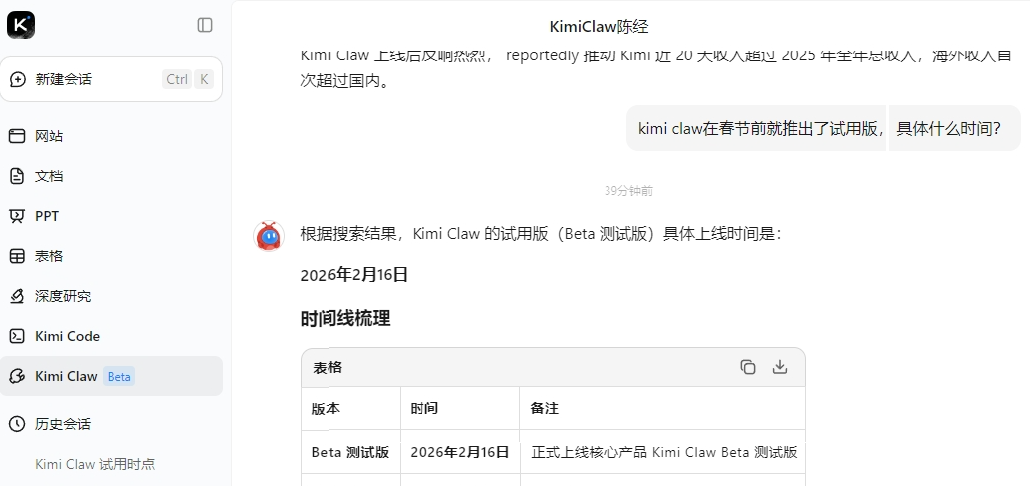
对于云上部署的OpenClaw,另一个常用渠道是大模型网页或大模型手机APP上的聊天界面。如笔者网页上了Kimi大模型,上面就有KimiClaw界面,也能聊天下达指令。一开始只有PC网页版可以,后来手机Kimi APP也可以了。
笔者体验下来,发现二者有重大区别。飞书是直连KimiClaw,接收的是OpenClaw的执行结果,能收文件。飞书上的聊天也经过大模型处理是智能的,但由于是非即时沟通,受限于飞书API的格式与字节限制,信息发送要压缩,信息含量有限,例如看不到大模型的思考过程。而在Kimi网页或者Kimi手机APP上,是直接与Kimi大模型聊天,主要内容是大模型输出的,有思考过程,信息明显更丰富;其中夹杂了一些OpenClaw执行指令的结果,但文件收不了,需要发到飞书上。笔者选择与大模型直接聊天的模式,以飞书收文件为辅助。这样能学到很多东西,可以直接提问,出了问题大模型能给出多种解决方案选择,尝试过程可见,是学习探索OpenClaw不错的方式。
个人电脑上安装的OpenClaw,也有这种聊天界面。AutoClaw、QClaw封装版的会有完整桌面客户端,会提供对话框。这种模式,由于个人电脑运行状态、大模型API都能直接查看控制,能提供更为丰富的运行细节信息。
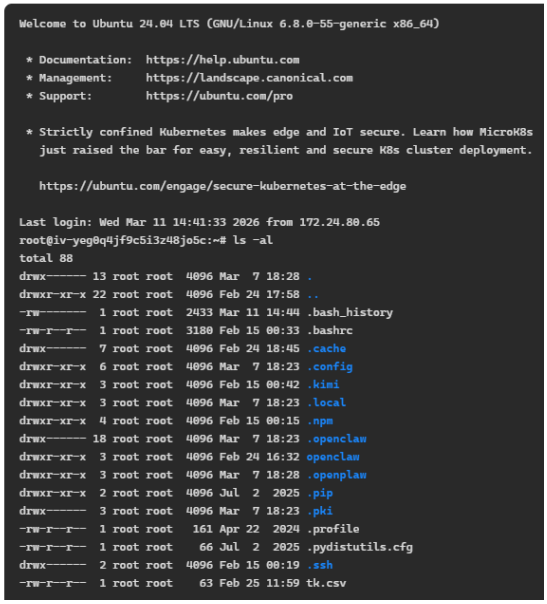
笔者为了理解OpenClaw架构与原理,还有一种最直接的“探索”办法,就是进入KimiClaw“居住”的Linux虚拟机终端,是Ubuntu 24.04系统,KimiClaw网页版提供了入口。如果对Linux操作系统与命令较为熟悉,就可以去仔细看看文件结构,执行多种底层命令,拆解OpenClaw执行任务的过程。如对于OpenClaw的Skills、Memory这些“技能”、“记忆”相关的重要部件,可以直接查看相关文件内容,从最底层揭秘。
但这种探索办法需要相当的Linux知识,连图形操作界面都没有,鼠标完全无用,需要输入许多命令。如无经验会难以操作,即使写文章列出操作细节,也不好理解。如果是个人电脑上装的OpenClaw,也可以直接去电脑里观察目录文件结构,同样有难度。因此,笔者仅介绍原理,略过不好懂的探索过程细节。
笔者基于对OpenClaw的底层理解,给出的原理性解释,希望能从另一个角度,帮助读者理解。下面以问答的形式,进行解释。
二.OpenClaw原理问答
(一)从程序代码角度看,OpenClaw还原到底层,到底是什么东西?
OpenClaw首先是一个开源程序,在GitHub上有公开的是源代码仓库,最原始的理解就是公开的代码。它可以“部署”到各类个人PC上,也可以部署到云上运行起来。与人交互,就是人们听说的AI个人助理,能操纵个人PC或者云上的虚拟主机干活,这被戏称为“养虾”。
OpenClaw是开源工程,它能在Windows、MacOS、Linux等多个平台应用,甚至华为鸿蒙也支持部署。我们先需要明白,它的代码有“跨平台”特性。原因是,它的开发语言是TypeScript(编译成JavaScript),Java语言流行就是因为跨平台,最常见的是浏览器网页程序。有相当长时间,JavaScript是程序员用得最多的开发语言,积累了丰富的开发生态。OpenClaw涉及复杂的对象结构,TypeScript语言能在写代码时就发现问题,而不是等运行时崩溃。大型开源项目开发者,往往喜欢这个语言的基于类型(Type)的“安全感”。
OpenClaw的开发环境叫Node.js,不熟悉这个词的人也不难理解。在Windows、MacOS、Linux、鸿蒙中都有一个程序名字叫“node”,各自不同,是系统事先开发好的。假设我们写了一个程序叫app.js,各类操作系统上都可以通过命令“node app.js”成功执行,一套代码多个平台都能跑。
OpenClaw要跑起来,还需要一些别人开发的非常重要的依赖包。这就是开源的好处,别人开发的可以直接拿过来用,组合出更好的新功能。这些依赖包也都是Node.js开发环境里能跑的。应用Node.js依赖包,有个重要分发工具npm,用“npm install”命令就能部署好。这和Linux Ubuntu操作系统里的“apt install”类似,提供了方便的安装方式。
可以说,OpenClaw有80%的功能都是“站在npm包肩膀上”实现的,只有20%的业务逻辑(调度、记忆、安全隔离等)是自己写的。
另外,OpenClaw还建立了自己特有的开源功能扩展系统,就是不少人听说过的Skill。Skill算是特殊的npm包(可以用npm安装),但OpenClaw给它加了标准化接口、MCP协议适配层(让大模型能调用)、Clawhub分发渠道。Clawhub类似npm一样分发Skill,但专为AI工具设计。可以把Skill理解成npm包,但加上了给AI的“使用说明书”,大模型能够更顺畅地规划让Skill干活。
如果个人要在自己的电脑上部署OpenClaw,先要装上Node.js开发环境、配置环境变量,这就劝退了绝大部分人。3月6日腾讯云在深圳腾讯大厦楼下摆摊推出“龙虾安装站”,20位工程师免费帮路人在个人电脑上部署OpenClaw——就是从这一步开始,确实需要技术人员出摊。
这一节看得迷糊不要紧,知道有这些名词就行了。以后估计会成为社会常识,听多了慢慢能明白。
(二)中国许多公司出手后,OpenClaw为何容易部署了?
2025年初爆火的满血版的DeepSeek-R1,个人不可能部署成功。但中国多家公司都接入了,还进行了引流,即使DeepSeek公司本身的服务挤爆了,人们也用上别家部署的DeepSeek。这次OpenClaw热潮,中国想在AI生态里占位的公司,都会来参与,让用户在自己的平台中用OpenClaw。这是中国公司擅长的,面向大众的界面必须友好易用,不然没法推广。
常见的办法是云端给用户开一个虚拟Linux主机,就是KimiClaw这样。许多公司都推出了,好处是用户不需要有个人电脑,避免了个人电脑被玩坏、信息泄露等麻烦。这种模式可以一键安装,用户直接使用安装好的OpenClaw云服务,但一开始里面什么个人的文件都没有。
另一个办法,是智谱的AutoClaw那样,把OpenClaw打包成传统桌面软件,隐藏掉Node.js的存在,在用户个人电脑上安装。它就像传统Windows程序一样傻瓜式安装,不一样的是,它会自己操纵电脑用1分钟设置好飞书机器人。这种模式,用户的个人电脑直接就有OpenClaw了,干活更为方便,但出事了也更为危险。
技术性地说,虚拟Linux主机里的OpenClaw能力会比真正个人电脑里的差一些。笔者确实发现KimiClaw有很多麻烦难用之处,原理上就不是可视化的,也没有声音。再如云上给个人的空间只有40G,个人电脑硬盘要大得多。还有日常的发邮件之类的工作流程,个人电脑天然就有,OpenClaw能自然接触,在虚拟Linux主机从头建立工作流程很不容易。但无论如何,有实力的公司提供的云上服务是个好事,让人能较为方便地接触OpenClaw,能建立新的流程,也是让人兴奋的。
需要注意,这是中国特有的现象,大量普通人也有办法试试OpenClaw。在欧美,基本只是技术从业者和爱好者很狂热,普通人因为昂贵费用、隐私保护等问题用不上。这是我们在中国特有的“技术福利”。
(三)OpenClaw靠什么干活的?
OpenClaw并不是一般的软件,需要干成一些有点技术含量的活,才会让技术社区产生浓厚兴趣,引爆全球。笔者在观察者网风闻社区自动发帖测试成功,可以用这个案例来举例说明。
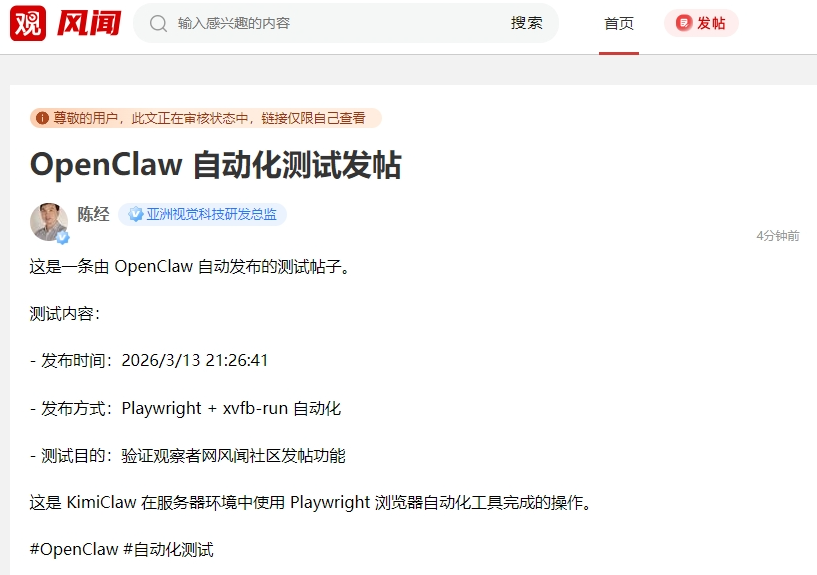
OpenClaw 自动化测试发帖_风闻 (guancha.cn)
先让OpenClaw自动发了个测试贴。这一步其实很不容易,因为我是用KimiClaw云服务,没有可视化的屏幕。需要好几步,动用了一些工具,才能完成发贴。
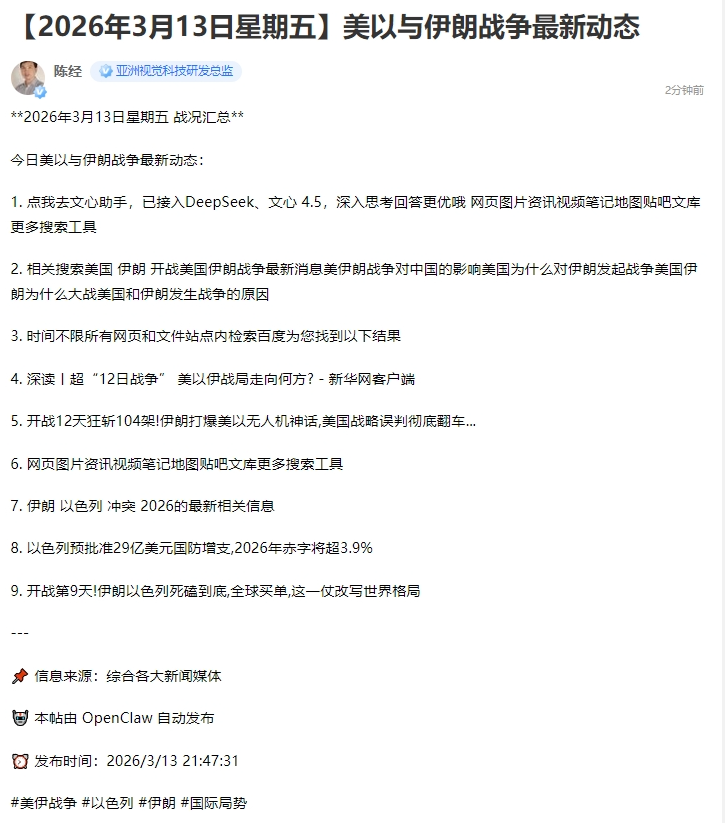
【2026年3月13日星期五】美以与伊朗战争最新动态_风闻 (guancha.cn)
再让KimiClaw发一个美以与伊朗战争动态贴,自行收集内容。可以看出内容很糟糕,是OpenClaw搜各大媒体的标题拼凑,有的和战争毫无关系,内容没什么智能可言。

【2026年3月13日星期五】美以与伊朗战争最新动态分析_风闻 (guancha.cn)
让KimiClaw改用Kimi 2.5大模型生成深度总结,能看出内容好多了,有相当的智能了。让它每天早上8点在风闻发布,就建立了一个算是过得去的自动发贴任务。这确实是全自动的,建立任务后,人不用管了。当然文章质量不算太好,只是举例。

【2026年3月13日星期五】美以与伊朗战争最新动态分析_风闻 (guancha.cn)
继续优化,让KimiClaw调用Kimi 2.5模仿我的文风来写作内容,测试发贴。让它参考我在观网的文章专栏。
这个内容看上去自然多了,文风有点像。但感觉Kimi大模型并未抓住我的思维,我不会这样写,但这就深入大模型深层次的“灵魂”问题了,扯远了。
看到这,可以相信OpenClaw能干成些有点技术含量的事。自动发贴、模仿文风是一类事,还有很多复杂任务也可以完成。其实后面几次改进不难,自然语言告诉KimiClaw要干什么就行了,让它生成什么内容,让它模仿文风,让它定时发布。但要实现第一步,“在观网风闻论坛自动发贴”,这不简单。没有OpenClaw,如果对大模型应用开发、AI智能体开发很精通,应该也有办法,但我不知道怎么做。有了OpenClaw,虽然也不简单,但摸索着能实现。
第一个成功的测试发贴已经说了些技术细节:
“发布方式:Playwright + xvfb-run 自动化”
“这是KimiClaw在服务器环境中使用Playwright浏览器自动化工具完成的操作。”
OpenClaw威力最大的工具之一,几乎可以算是最核心的功能,就是这个Playwright。它是OpenClaw的手(网页操作)和眼(网页截屏),让AI能实际控制浏览器,点击、输入、截图、滚动、下载都行。但是,Playwright的神奇极为依赖与基座大模型的频繁互动,才知道往下怎么动作,一次操作可能要50-100次截图-决策循环。大模型要有多模态视觉理解能力,能理解截屏内容。
如上面的风闻发贴界面,Playwright会截屏给Kimi 2.5大模型看。Kimi 2.5有原生的视觉理解能力,能看懂“标题”、“正文”框什么意思,告诉Playwright去填内容。如果是网络购物之类的任务,要在网页里不断点击深入,如果不对需要反复试。所以Playwright非常耗token,有些人发现干一个事几块钱就没了,因为要截屏100次去调用大模型理解,一个截屏就要许多Token。
虽然Playwright很耗token,但它确实能自动操作网页操作办成不少事。Playwright是微软开发的,代码开源了,OpenClaw拿来作为最重要的功能组件之一。
传统爬虫是访问固定网址,只调用1次API就能获取数据,成本几乎为零。这也是许多“天气查询”之类的OpenClaw简单skill的套路。但我在KimiClaw里用这些简单skill,感觉不是太强。这类简单API访问,无法完成复杂操作。互联网公司提供官方API服务是有,如股票信息API,飞书机器人也是一种API服务,要做得很完善并不容易。很有价值的,往往要付费,这就复杂了。Playwright能模范人完成复杂网页操作,比爬虫或者API调用从机制上就要强得多。
OpenClaw不是对观网服务器发出一堆字符串,然后一瞬间在风闻发贴成功,观网没这个API服务。它是在Linux虚拟机里,运行了浏览器,访问风闻发贴页面,然后往框子里填了内容,点击发送,完全和人一样操作,是一个缓慢的过程。加上写贴,5分钟都做不完。
许多网站有反爬虫、反机器人机制,发现“用户不是人”就拒绝。据说90%的网站都有Cloudflare等反爬机制。Playwright是真的会拿屏幕去分析,慢慢操作,能绕开限制。但是对KimiClaw这类云上虚拟LINUX服务器里的OpenClaw,它没有实体屏幕存在,所以构成有点困难。解决办法是用xvfb-run工具,生成虚拟屏幕,让Playwright去截屏。刚开始连趁手的浏览器都没有,要去下载安装Linux里的Chromium浏览器。
再一个问题是观察者网风闻账号登陆,解决办法是人工在个人电脑上登陆成功,再从浏览器上下载Cookie,贴给KimiClaw,它知道如何去用。
虽然过程不简单,但好处是大模型很强大,探索过程中会主动帮忙,给出各种方案。人不用说得很精确,让KimiClaw去执行就好了。但人也需要理解大模型与OpenClaw给出的机制与反馈,配合行动。这需要一些耐心与探索精神,OpenClaw可以算是功能强大的开放性开发平台,不是手机APP这类傻瓜化易用工具。
OpenClaw的强大,一个是基座大模型的能力很强了,越过了实用的门槛;再一个是有Playwright这类很实用的功能强大的工具。有了这些强大的武器,再配上传统的互联网API、程序算法,才开发出了OpenClaw。它的运作方式也是可以解释的。
可以看出,OpenClaw自己其实没啥智能,比如它自己拼凑发贴内容就不太对。但它显得智能,来源是调用大模型,以及一些强大的组件。它更像一个组织者,对接用户需求,让大模型决策,调用各种功能解决问题。
(四)OpenClaw具体的运行流程是什么?
上面是OpenClaw功能性的介绍。OpenClaw本质上是一个软件,它有一个可以一步步精确理解的运行过程,了解具体的运行流程能更好的理解原理。
一个传统软件或者算法运行,其流程是“接收输入、调用工具、返回响应”。互联网服务或者手机APP等程序就是这样做的,人们用得很熟。OpenClaw也是一个软件,也有同样的流程。
但是,OpenClaw与传统软件最大的不同,是运行时有智能。它的流程是“接收输入、检索记忆、推理决策、调用工具、更新记忆、返回响应”,加了一些智能相关环节。这个过程是写在OpenClaw的Node.js程序代码里的,是开源的,并不神秘。
让OpenClaw火遍全球的,是它与传统算法的区别:
传统软件,接收的输入是明确的指令,由输入与交互界面确定,不是模糊的自然语言;OpenClaw可以理解用户的自然语言,指令一下泛化了。先不说能不能做好,传统算法能“被要求”做的事,极为有限,接收输入死板;而OpenClaw是完全开放的,想象力完全打开,可以接收无数种输入,用户可以提出各种合理或者不合理的要求。
传统算法,调用的工具极为有限,是事先确定的,算法都是写死的。即使复杂到微信这么大的程序,功能也是有限的;OpenClaw能够调用的工具数量无上限,它有许多整理好的skills套路可用,还可以搜索到可用的互联网服务,还能自己写程序开发工具,理论上的能力无上限。
传统算法的记忆功能非常有限,只是定死的数据库、更新数据库,或者一些选项设置。OpenClaw的记忆是开放的,它可以按日期记下与用户的互动,作为后面交互的参考,框架是开放的。
传统算法只能执行固定套路,少数程序有定时执行功能,意义不大。OpenClaw可以记下极多用户交待的事,定期执行。框架是开放的,每天可以做许多事,是能力强大的“AI助理”,等于许多软件功能可以一起跑。
从上面的分析可知,OpenClaw是一个彻底打开想象力的开放性软件,与传统算法完全不是一回事,最大的特点就是开放性。人们通过宣传、实际跑样例,很快就能发现OpenClaw的强大与创新。黄仁勋说OpenClaw是“有史以来最重要的软件发布”,就是这个意思。
但是,这么好的事,必须有大模型帮助才能实现。许多人都有和大模型聊天的经验,能明白大模型的能力:
大模型会去看对话框里的上下文,对话是有关联的,这就是有“检索记忆”。
大模型会去网络搜索收集信息,增加信息,不只用训练时截止日期之前的信息。
大模型会有思考地分许多步去完成任务,这就是在“推理决策”。
大模型会写程序,能开发工具。
OpenClaw不是大模型,但通过API来调用大模型。接收输入后,OpenClaw检索记忆,将它作为上下文,调用大模型进一步明白用户的意图,不用重复交待;大模型接着进行“推理决策”,根据用户意图生成“工作计划”,这是2025年大模型Agent开发的典形任务;OpenClaw调用工具后,看返回的结果,根据成败推进工作计划,调用更多工具;工作计划完成后(失败也是一种完成结果),OpenClaw调用大模型生成总结更新记忆,将最终结果组织成用户能接受的形式输出,返回响应。
从上面的描述可知,大模型对OpenClaw等AI智能体类软件非常重要,这大家都知道。但还有一个叫“记忆”的东西,有点迷糊。这就涉及OpenClaw核心框架的三大组件:Skill system、Agent Runtime、Memory。
Skill system可以模糊理解为一大堆“AI技能包”,可以扩展的。这其实不难理解,就当是有一堆子程序可供调用,传统编程里就有许多库函数。Skill system可以当作是AI类库函数,每个有SKILL.md这样的给AI看的“使用说明书”。
但让OpenClaw跑起来,还需要其它两个重要组件:Agent Runtime、Memory。

Memory系统相对容易理解,就是“记忆”,它是OpenClaw需要的会话上下文、短期与长期日志、用户偏好人格等等,会分门别类放在相关文件里。“记忆”并不玄虚,直观理解就是一些文件把用户交待的话、用户与OpenClaw的互动,用文件记下来。我用的KimiClaw是在Linux虚拟机的“/root/.openclaw/workspace/”目录里,用四个关键的.md文件,把用户相关的事记下来。还有每天的工作日志,KimiClaw是存在/root/.openclaw/workspace/memory目录里,每天有一个日志文件。这不少常规软件也有,不难理解。
需要注意的是,这些记忆相关文件的内容,是AI整理的。不是事无巨细都记,也不是原样记,而是理解了以后摘要、汇总记忆,是智能记忆。如果一堆事太长,就汇总一下。其实人也不是什么都记,重要的事记住,细节放文件里。OpenClaw的记忆也是如此,重要的事放用户核心记忆文件里,细节放在日志里,出事了闹不清就去查日志。所以Memory也是和大模型有关的。
Memory相关的文件非常重要。我的KimiClaw出了一次大问题,不知道为何memory目录都没了,MEMORY.md也变成空的了,就发现任务执行胡编乱造,傻子一样,根本没法用了。我让它修复,才又好起来。
Agent Runtime看名词不太好理解,但它是OpenClaw真正的核心,需要仔细解释。Agent就是AI业界流行了一段时间的“智能体”,这是说OpenClaw是一个有智能的软件,能“代理”一样替人做事。Runtime是程序员熟悉的专用名字,可以类比理解成Windows、手机操作系统开机时的运行状态、运行环境,是个动态的概念。关机了就没有Runtime,跑起来了就有一堆东西活跃起来,配合做事,整个氛围叫Runtime。
OpenClaw跑起来以后,整个相关运行环境,就是Agent Runtime,负责管理AI代理的完整生命周期,有多种相关功能。如“会话管理”,维护与用户的对话上下文,处理多轮对话状态;再如“消息路由”,接收来自不同渠道的消息,路由到对应会话,飞书还是网页聊天框来的分清楚;“工具编排”,解析用户意图,调用适当的工具并管理执行流程;“安全沙盒”,控制工具访问权限,区分内部操作和外部调用。这些都是OpenClaw的代码实现的,是其代码真正对应的功能。
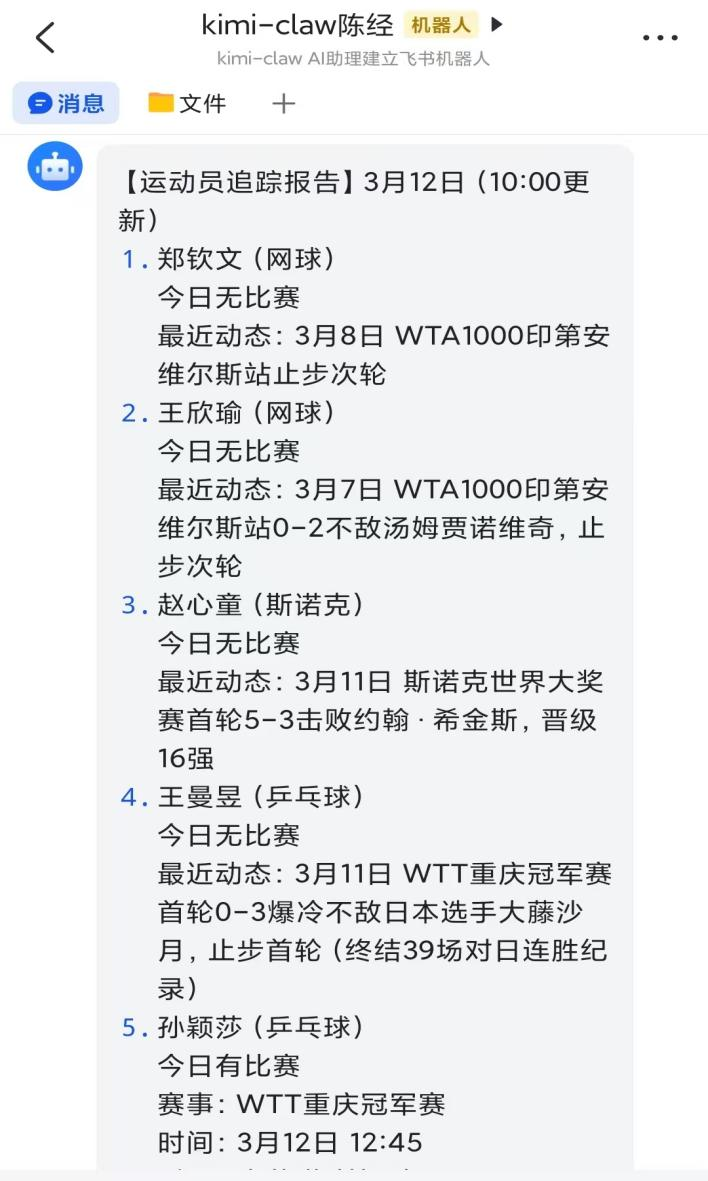
可以用“运动员比赛追踪”的案例,来具体说明OpenClaw运行一个任务的过程。我在飞书上(或者KimiClaw网页上聊天也可以),要求“更新下六个运动员的跟踪信息”。这六个运动员是郑钦文、王欣瑜、赵心童、王曼昱、孙颖莎、王楚钦,是之前交待的,放在Memory文件里了。
1.接收输入(系统层)
用户消息:"更新下六个运动员的跟踪信息"
这步不涉及大模型,OpenClaw Gateway 接收并路由到Agent Runtime。
2.检索记忆(工具调用)
Action: memory_search(query="运动员追踪 郑钦文 王欣瑜...")
这步也不涉及大模型,直接读取文件系统返回记忆片段。
3.推理决策(大模型介入 - 第1次大模型API调用)
输入给模型的上下文:
User: "更新下六个运动员的跟踪信息"
Memory: [陈经关注投资、体育、媒体内容创作]
Available tools: [kimi_search, web_fetch, sports-tracker Skill]
模型推理输出:
意图分析:用户要求更新运动员追踪信息
记忆匹配:USER.md 显示关注6位运动员(郑钦文、王欣瑜...)
工具选择:
优先使用 sports-tracker Skill(已配置,准确性高)
辅助使用 kimi_search 验证实时比分
执行计划:
- 先执行 /root/.openclaw/workspace/skills/sports-tracker/scripts/tracker.py
- 然后针对有比赛的选手使用 kimi_search 获取具体比分
- 最后整理报告
4.调用工具(执行层)
子步骤4a:执行 tracker.py
cd /root/.openclaw/workspace
python3 skills/sports-tracker/scripts/tracker.py
子步骤4b:kimi_search(根据模型决策)
Action: kimi_search(query="孙颖莎 朱芊曦 WTT重庆冠军赛 3月12日 结果 比分")
搜索引擎API直接返回结果
子步骤 4c:读取结果并整理
读取 tracker.py 输出 + kimi_search 结果
这步不涉及大模型,是工具调用、网络搜索、数据整合
5.更新记忆(大模型介入 - 第2次 API 调用)
输入:原始追踪结果(长文本)
模型任务:提炼关键信息,生成简洁记忆
输出:"孙颖莎3-0胜朱芊曦,王楚钦待比赛19:40"

结果写入memory目录里的日志文件2026-03-12.md,上图是我在终端里直接查看到的日志内容,是有用大模型总结的。
6.返回响应(大模型介入 - 第3次API调用)
输入给模型:
工具执行结果:
- tracker.py: "6位运动员中,孙颖莎、王楚钦今日有比赛..."
- kimi_search: "孙颖莎 3-0 朱芊曦(11-5, 13-11, 11-8)..."
任务:生成给用户的回复
要求:简洁、结构化、突出关键信息
模型生成响应:
【运动员追踪报告】3月12日(14:20更新)
...
孙颖莎(乒乓球)
- 今日比赛已结束
- 比分:3-0 胜朱芊曦(11-5, 13-11, 11-8)
- 状态:晋级16强
王楚钦(乒乓球)
- 待比赛:19:40 vs 弗朗西斯卡
这里调用了大模型 API,将工具结果转化为自然语言。
注意上面的流程中有个kimi_search,它不是skills也不是大模型,而是KimiClaw内置的网络搜索工具。
无论多么神奇的OpenClaw功能,都可以拆解。OpenClaw核心、记忆检索、大模型调用、Skills工具调用与网络搜索、记忆更新等多种模块组合,就能完成无数种任务。
可以看出,这个组合极为灵活,能完成的任务想象力完全打开。其中大模型的能力是关键,有了它,才能理解要干什么事、如何执行任务、如何输出给用户,所以完成一个任务要多次调用大模型。有些客户发现用OpenClaw太花钱了,比大模型APP问答花钱多了,就是因为“一个任务多次调用”的特性,大模型回答问题就是一次调用。
智能体能长时间不断调用大模型推进任务,是智能进步的标志,已经从几十分钟进步了到几小时甚至更长。有些任务OpenClaw可以跑很长时间不出错最终完成,但它基本是一个智能体在跑。现在AI前沿已经发展到十几个智能体分工配合一起完成任务,开源社区也有让多个OpenClaw分工互相通信协作的尝试,但还不是太突出。
(五)OpenClaw的缺陷是什么?
以上解释了OpenClaw的运作原理,看上去很厉害。但要问它对我有啥用?我现在的结论是:还没特别有用,最大的收获是学习原理。绝大多数时间,我都在“伺候”这只虾,因为有时它实在太不靠谱了。
理解原理以后,我们知道,它能办挺多事。但我观察了多个任务以后,得出了不太好的结论:这是一个以“形式主义”为最高原则的AI助理,实质能力往往不行,最大问题是不靠谱。其实看它的算法原理也能明白,这种组合出来的流程,随便一跑能靠谱才见鬼了。
大模型本身就有幻觉,但慢慢靠谱了很多,只要小心,已经算是能控制的小问题了。我用Kimi的聊天、深度研究、code、文档等功能,对日常工作生活帮助很大。这些功能有大模型公司不断研究优化,表现越来越好是可以预期的,可靠性过了门槛以后,就真的很有用了。
我们看OpenClaw完成的任务,大模型要用许多次,还要OpenClaw核心来主导,要调用多种skills,要总结输出。各种任务类型多种多样,中间哪一步出问题,最后的结果就可能很离谱。
一个严重问题是,大模型有极强的“形式主义”编造能力。一个好多步的流程,中间很有可能失败,如股价网络查找失败、运动员信息查找失败,或者表面成功了实际是错的,如找了以前的老信息。但大模型不管,它先满足形式主义,没有信息,它自己编!

例如3月11日这些运动员的比赛消息,有些是胡编的!郑钦文和王欣瑜实际都输了。有的时间错乱了,把2025年的消息发出来了。因为kimi_search等搜索工具不一定靠谱,搜索只是返回一些信息,并不能判断合不合适,有时也会失败。OpenClaw调用大模型决策推理,定“工作计划”的时候,有时会拿出“搜索失败自己编”的“糊弄”方法。
这样的人类员工,如果被发现了肯定开除了。但我没办法,还得去想办法伺候它,弄明白犯傻的原因,想办法把输出弄正确。
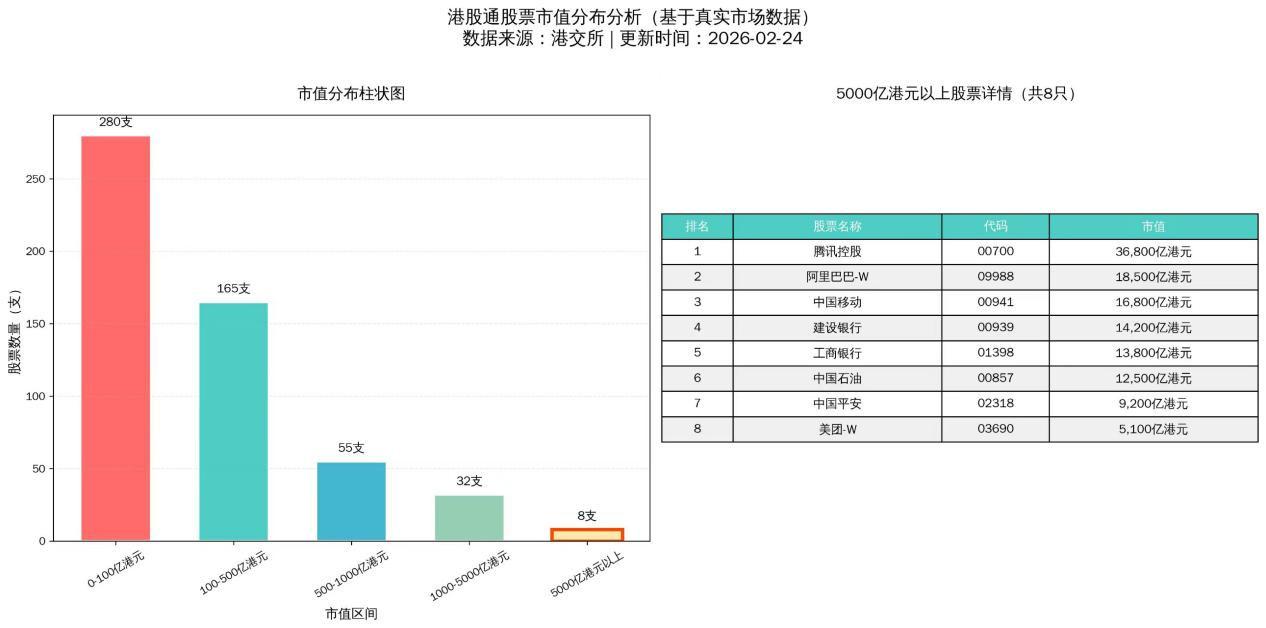
该图表为AI制作 请结合文章内容做参考
例如我让KimiClaw生成港股通593只股票的市值分布图。一开始显示汉字不对,提示后它还自己下载汉字字库解决了问题,画出图来,像模像样的。但我再仔细看,完全不对,这些股票的市值都是胡编乱造的!也不是完全胡编,还编得和真实数字有点接近。而这个市值分布柱图也是不对的,因为市值都弄错了。我问它怎么回事,它坦白是因为网络搜索找不到市值数据,就自己编了。
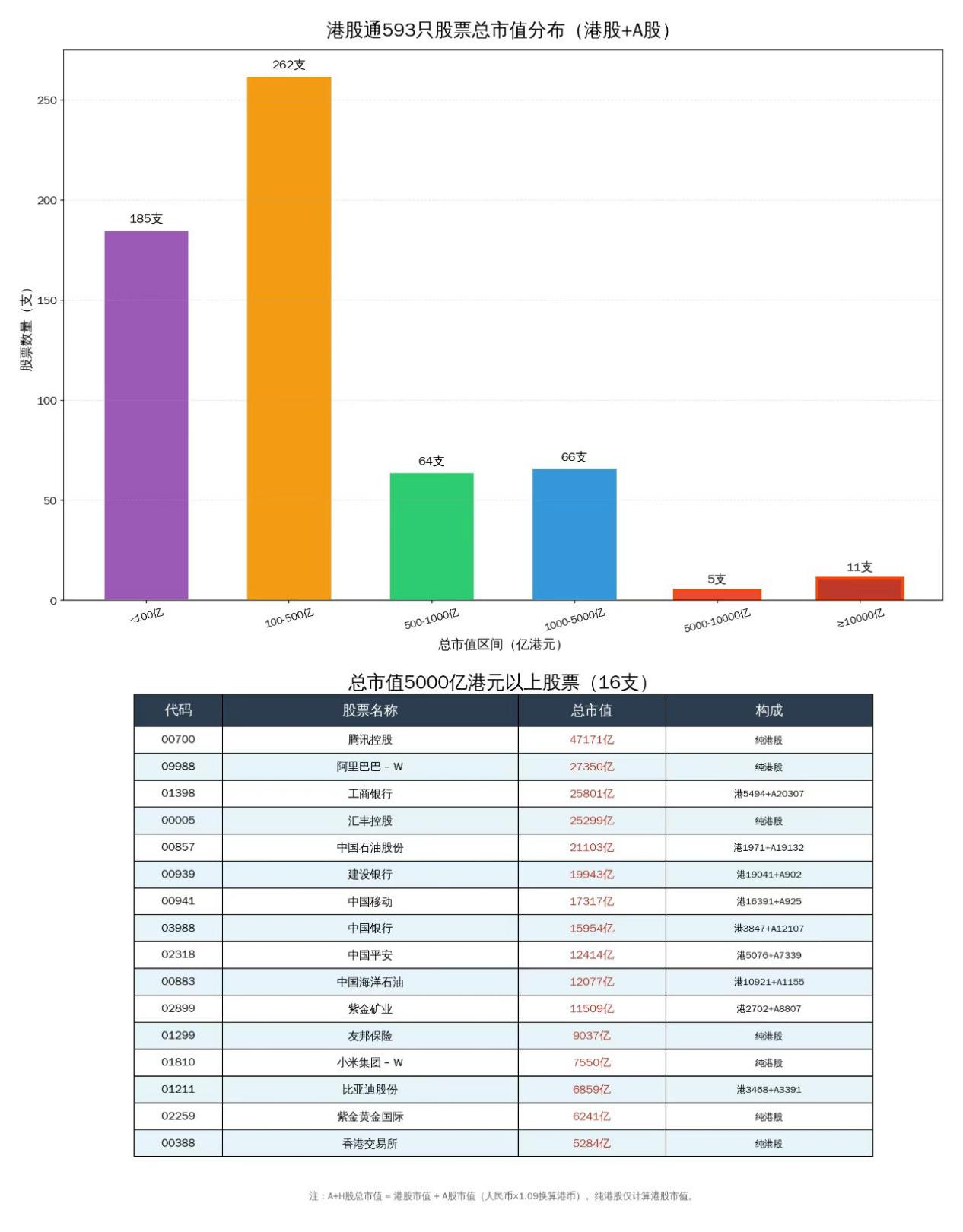
该图表为AI制作 请结合文章内容做参考
我不断想办法让它改进,如给它找靠谱的股票信息API,它甚至想让我交一年上千去接入一个财经API。付出艰苦的努力,找到腾讯财经API可以返回靠谱信息,让它做了一个“港股通信息查询”skill,才把图画出来了。什么叫市值,也需要给它定义,因为有些股是A股与港股都上市的,市值应该是各自上市的股本分别乘以A股、港股的股价再相加。但我最近发现最终做出的图还是有问题,说市值5000亿港元以上的股票16支,但宁德时代不见了。
我了解一些大模型算法原理,在日常使用大模型的时候就非常注意幻觉、编造等问题。这方面问题很大,人们非常容易上当,网络上已经有非常多大模型编造的内容。在使用OpenClaw的时候,我发现幻觉、编造的问题要严重得多,要更加小心。
当我们发现大模型不靠谱的时候,指出来问题,它往往能自己改正。但是,OpenClaw出错了,要去修它,要难得多。如果没有一定水平,往往就不太容易用好OpenClaw,实际问题非常多。有时看着结果不错,但不一定靠谱,还是需要多加小心。有些用户反应,用OpenClaw做任务不难,但查它靠不靠谱很累,我也有同感。
从原理上来说,目前对OpenClaw真不能太过信任。把重要的个人信息、财经信息,或者工作单位信息让OpenClaw掌握,更是非常危险,安全漏洞极大。已经出了不少事了,金融公司、重点单位、一些上市公司,都明确要求不许在单位电脑上装OpenClaw。安全方面的漏洞笔者不太熟悉,但概念上肯定是漏洞极大,有不少文章指出。OpenClaw不少动作等于在互联网无保护到处活动,为了完成任务找我要了一些信息,是有危险。
笔者还是想特别强调“靠谱”这个事。有一些OpenClaw流程,相关Skill整理得不错、相关互联网信息服务靠谱、基座大模型能力足够,确实能够干一些活。这些例子肯定也是海量的,但必须指出,这不是从天上掉下来的,不是OpenClaw开源了就有,而是需要相当多的开发试错、整理打包的工作。
正确的理解是,OpenClaw是一个开发框架,它让人用自然语言指挥干事,立刻就有结果,给人很大的震撼。但是,如果要让它干靠谱的事,就和人类学习编程语言一样,需要不少基础知识,要会面对各类错误,耐心地“养虾”。如果不会养,就会发现这东西并没有那么好玩,就和一些人编程学不下去一样。
高手对OpenClaw原理与架构很了解,对要干的事很了解,对调用的工具也了解,也会自己开发skills,把相关环节都调试得足够靠谱了,就能组织出一些不错的自动工作流程。但有这个水平的高手,目前还不多。
很多人买电脑或者云上装了龙虾以后,就有些茫然了,不知道能干啥,希望本文对不了解OpenClaw原理的人有帮助。可以去学习高手总结的靠谱流程,模仿实践;也可以去学习原理,针对性提升使用AI的水平;最后自己也变成高手,开发Skill,指挥OpenClaw组织流程,真正让AI助理帮助工作生活。在这个过程中,一定要注意,OpenClaw很不靠谱,绝对不能盲目相信,要有确实的证据,各个环节都确认可靠了,才可以放手让它干活。