如何使用python爬虫+正向代理实现链家数据收集
admin
2023-06-28 07:23:52
0次
一、选择目标网站:
链[lian]家[jia]:https://bj.lianjia.com/
点击【租房】,进入租房首页:
这就是要爬取的首页了;
二、先爬取一页
1、分析页面
右击一个房源的链接,点击[检查],如图: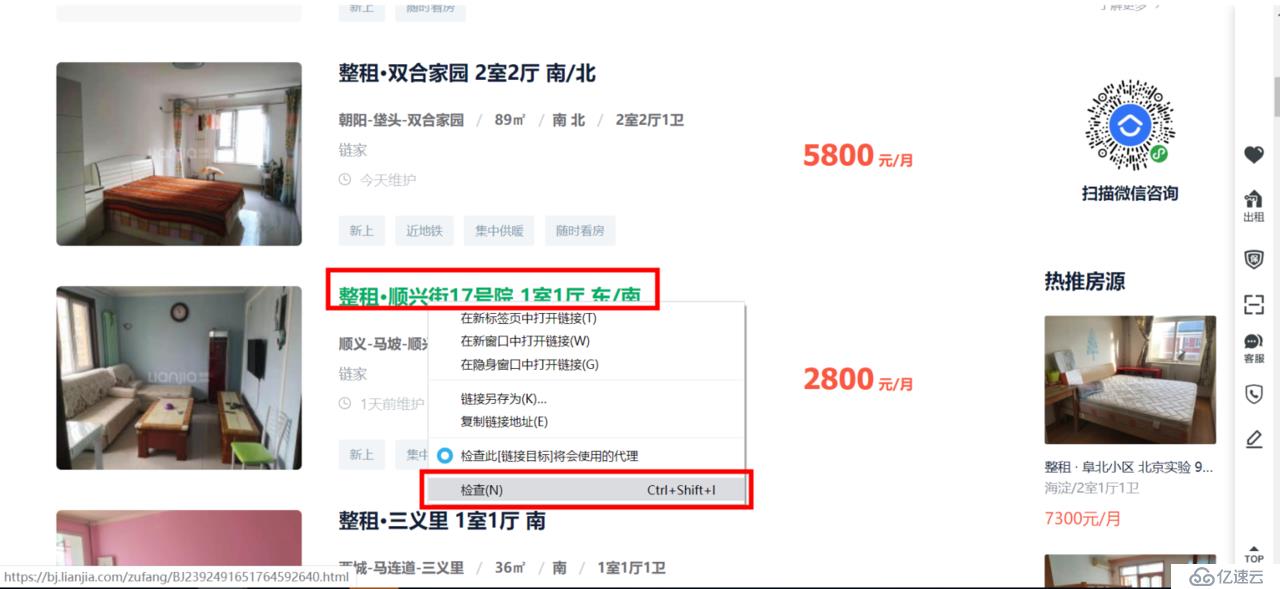
进入开发者模式,
此时可以看到 a 标签中的链接: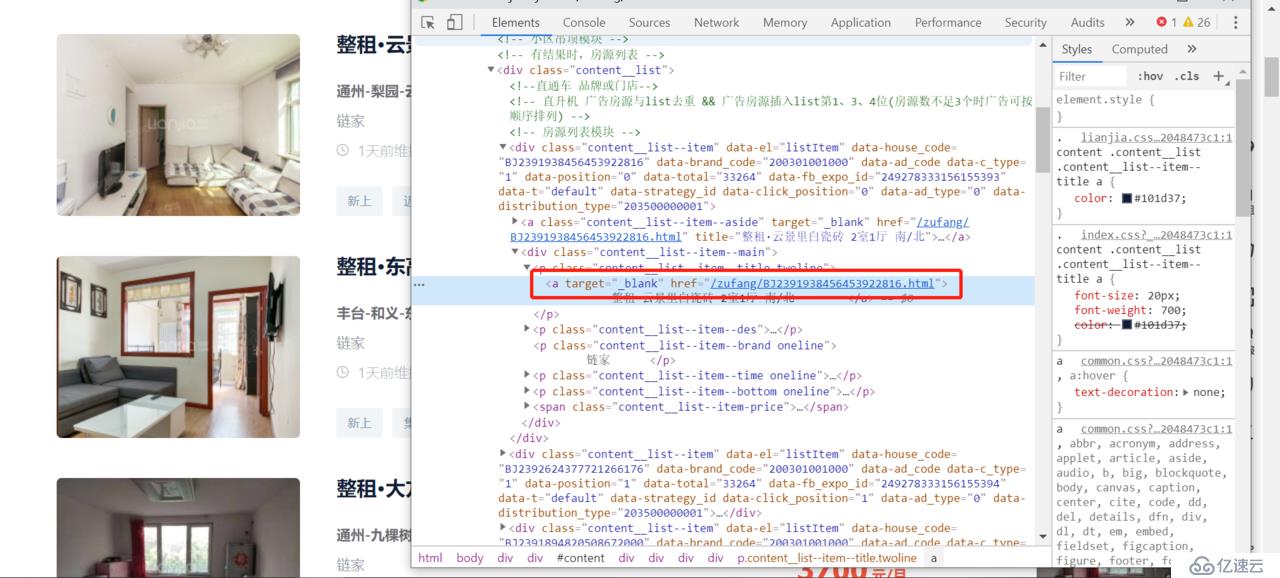
使用 xpath 就可以把链接提取出来,不过该链接是真实 url 的后半段,需要进行字符串拼接才能获取到真正的 url;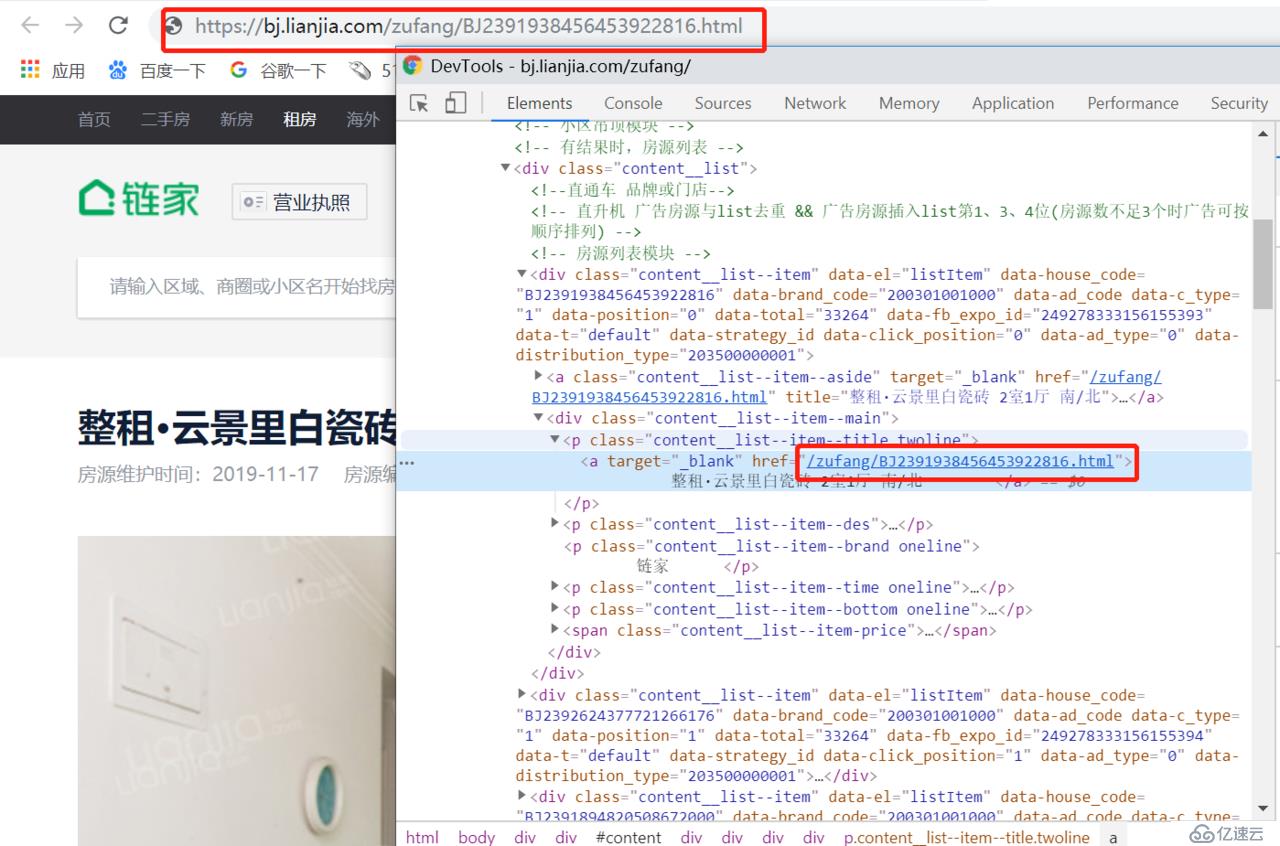
后面会在代码中体现;
爬取的信息暂且只对下图中标出的进行爬取: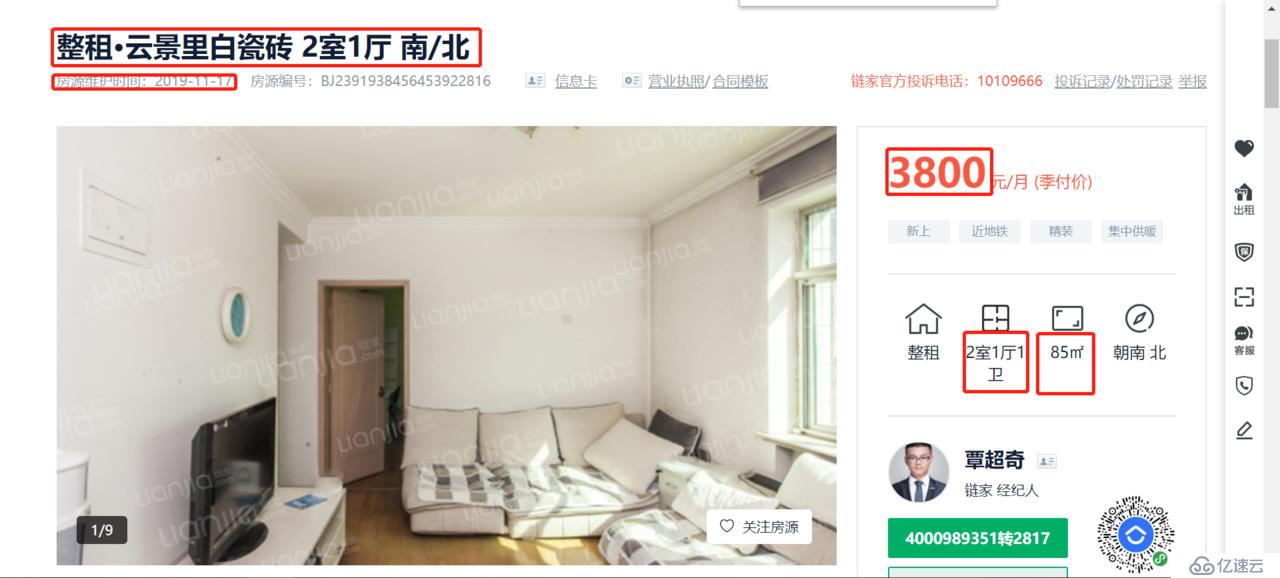
包括 标题、时间、价格、房间格局、面积 ;
三、对全部页面进行爬取
1、分析页面 url
点击租房,找到其跳转到的网页:https://bj.lianjia.com/zufang/
对,这就是要爬取的首页:
我们往下拉到最底端,点击下一页或者其他页,
第 1 页:https://bj.lianjia.com/zufang/pg1/#contentList
第 2 也:https://bj.lianjia.com/zufang/pg2/#contentList
第 3 页:https://bj.lianjia.com/zufang/pg3/#contentList
.
.
.
第 100 页:https://bj.lianjia.com/zufang/pg100/#contentList
通过观察 url 可以发现规律:每一页只有 pg 后面的数字在变,且与页数相同;
拼接字符串后使用一个循环即可对所有页面进行爬取;
四、源码
开发工具:pycharm
python版本:3.7.2
import requests
from lxml import etree
#编写了一个常用的方法,输入url即可返回text的文本;
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
else:
print("请求状态码 != 200,url错误.")
return None
for number in range(0,101): #利用range函数循环0-100,抓去第1页到100页。
initialize_url = "https://bj.lianjia.com/zufang/pg" + str(number) + "/#contentList" #字符串拼接出第1页到100页的url;
html_result = get_one_page(initialize_url) #获取URL的text文本
html_xpath = etree.HTML(html_result) #转换成xpath格式
#抓去首页中的url(每页有30条房源信息)
page_url = html_xpath.xpath("//div[@class='content w1150']/div[@class='content__article']//div[@class='content__list']/div/a[@class='content__list--item--aside']/@href")
for i in page_url: #循环每一条房源url
true_url = "https://bj.lianjia.com" + i #获取房源的详情页面url
true_html = get_one_page(true_url) #获取text文本
true_xpath = etree.HTML(true_html) #转换成xpath格式
#抓取页面题目,即:房源详情页的标题
title = true_xpath.xpath("//div[@class='content clear w1150']/p[@class='content__title']//text()")
#抓取发布时间并对字符串进行分割处理
release_date = true_xpath.xpath("//div[@class='content clear w1150']//div[@class='content__subtitle']//text()")
release_date_result = str(release_date[2]).strip().split(":")[1]
#抓取价格
price = true_xpath.xpath("//div[@class='content clear w1150']//p[@class='content__aside--title']/span//text()")
#抓取房间样式
house_type = true_xpath.xpath("//div[@class='content clear w1150']//ul[@class='content__aside__list']//span[2]//text()")
#抓取房间面积
acreage = true_xpath.xpath("//div[@class='content clear w1150']//ul[@class='content__aside__list']//span[3]//text()")
print(str(title) + " --- " + str(release_date_result) + " --- " + str(price) + " --- " + str(house_type) + " --- " + str(acreage))
#写入操作,将信息写入一个text文本中
with open(r"E:\admin.txt",'a') as f:
f.write(str(title) + " --- " + str(release_date_result) + " --- " + str(price) + " --- " + str(house_type) + " --- " + str(acreage) + "\n")最后将爬取的信息一边输出一边写入文本;当然也可以直接写入 JSON 文件或者直接存入数据库;
相关内容
热门资讯
南开大学通报生科院院长等3人学...
情况通报针对我校教师陈某相关论文数据存疑的问题,学校第一时间成立由校内外专家组成的调查组,严肃认真开...
原创 快...
最近荷兰就稀土供应问题表态,称若中国停止相关供应,荷方或将采取各类应对举措。不少业内人士对此提出质疑...
普京:已将2025年12月袭击...
据俄罗斯卫星社5月29日报道,俄罗斯总统普京向记者表示,俄罗斯已将2025年12月袭击瓦尔代总统官邸...
太意外,最不爱生娃的国家,突然...
作者 | 子期最不爱生娃的国家,突然大逆转了?根据韩国官方的最新数据,今年1-3月韩国出生人口7.5...
标榜无党派却贴满MAGA标签!...
据美媒Axios新闻网报道,近日,为纪念美国建国250周年打造的“自由250(Freedom 250...
外卖大战后超千万骑手过剩?行业...
5月29日,据东方财经援引媒体报道,随着平台补贴持续退潮,外卖行业“骑手过剩”问题日益凸显。据瑞银(...
超载客车追尾致13死,司机身亡...
围绕G40沪陕高速河南南阳桐柏毛集段发生的重大道路交通事故,调查处置工作仍在进行中。据央视新闻报道,...
“老师,我晚点到,救个人!”
近日,江苏沭阳县潼阳中学高二(4)班班主任陈凌燕接到了学生冯思逸的请假电话原来,在返校路上冯思逸目睹...
模仿黄仁勋走红后,“我现在很害...
5月,英伟达CEO黄仁勋在华访问期间,身着他标志性的皮衣,一头扎入北京的“烟火气”之中。他在街头大口...
原创 北...
5月29日,北方华创宣布,其首台600mm×600mm面板级封装去胶设备(Descum)成功出厂,标...