如何使用python3抓取微信公众号文章,了解一下?
admin
2023-01-21 08:40:04
0次
通过微信公众平台的查找文章接口,抓取我们需要的相关文章
1.首先我们先看一下,通过正常的登录自己的微信公众号,然后用文章搜索功能,搜索一下我们需要查找的相关文章。
- 打开https://mp.weixin.qq.com
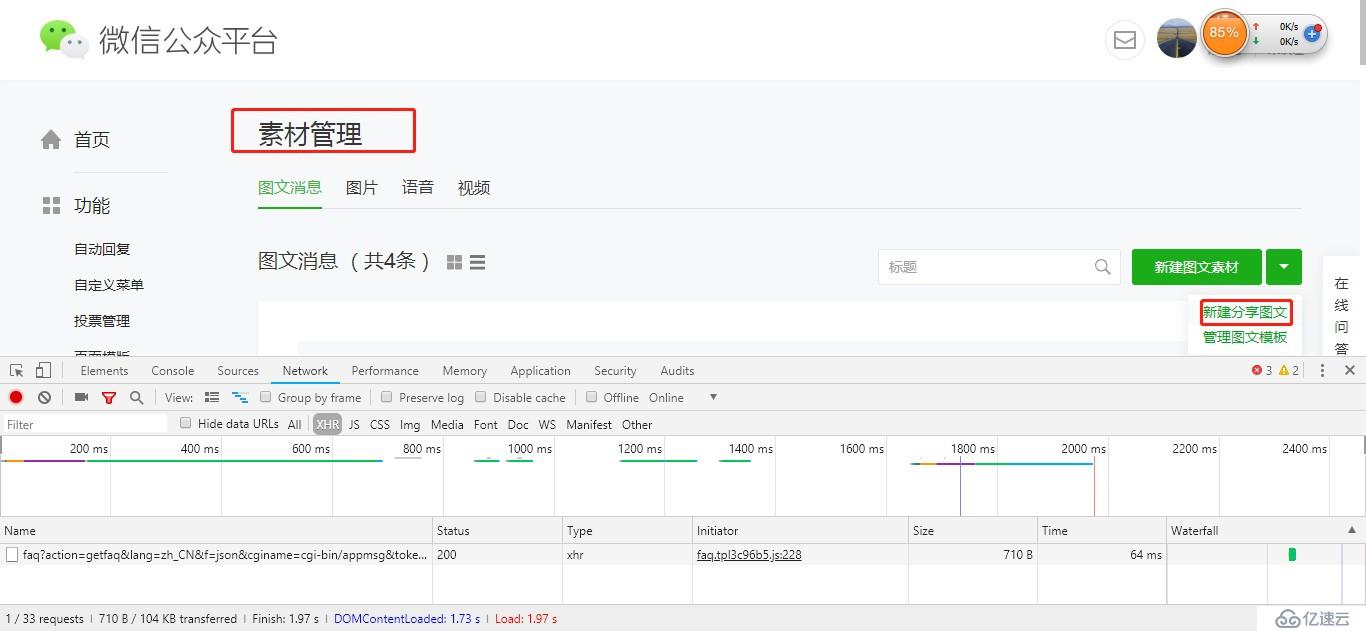
- 登录公众号,打开素材管理,点击新建分享图文
- 打开一个文章搜索接口
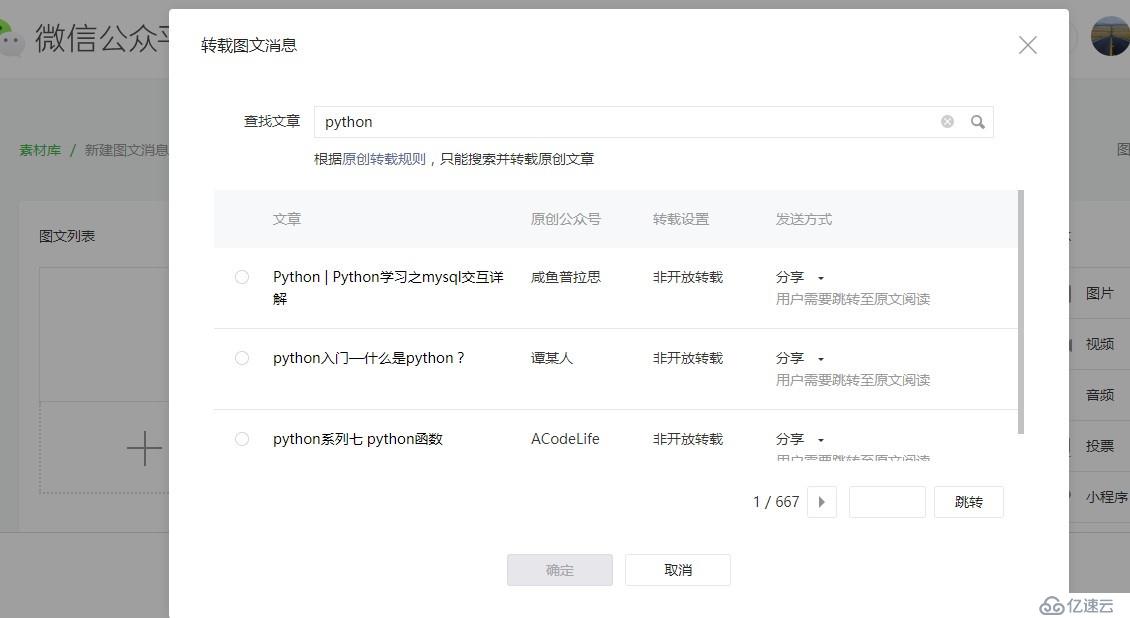
- 输入要搜索的内容后,可以搜索到相关文章的标题、出自哪个公众号等信息。
2.实现思路
这里有一个问题,打开微信公众平台首页,输入账号密码后需要使用管理的微信号扫码确认一下才能最终成功登录微信公众号,这个要怎么解决呢?
我们可以第一次登录的时候按正常的流程输入账号密码,扫码登录,拿到cookies,保存下来以便后面调用这个cookies来验证登录;当然cookies是有失效时间的,但是我在测试的时候好像过了3-4个小时还能用,够做好多事情了。
- 基本思路:1.通过selenium驱动浏览器 打开登录页面 ,输入账号密码登录 ,获取登录后的cookies,保存cookies以便调用;2.拿到cookies之后 ,去请求首页 登录后直接跳转到个人首页,打开文章搜索框,找一些需要的信息;3.拿到有用的信息后,构造data数据包 ,模拟post请求, 然后返回数据,拿到数据之后 ,解析出我们需要的数据。
3.获取cookies,话不多说,贴个代码
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
from selenium import webdriver
import time
import json
driver = webdriver.Chrome() #需要一个谷歌驱动chromedriver.exe,要支持你当前谷歌浏览器的版本
driver.get('https://mp.weixin.qq.com/') #发起get请求打开微信公众号平台登录页面,然后输入账号密码登录微信公众号
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').clear() #定位到账号输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').send_keys('这里输入你的账号') #定位到账号输入框,输入账号
time.sleep(3) #等待3秒后执行下一步操作,避免因为网络延迟,浏览器来不及加载出输入框,从而导致以下的操作失败
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').clear() #定位到密码输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').send_keys('这里输入你的密码') #定位到密码输入框,输入密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[3]/label').click() #点击记住密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[4]/a').click() #点击登录
time.sleep(15) #15秒内扫码登录
cookies = driver.get_cookies() #获取扫码登录成功之后的cookies
print(cookies) #打印出来看看,如果超时了还不扫码,获取到的cookies是不完整的,不能用来登录公众号,所以第一次必须扫码登录以获取完整的cookies
cookie = {} #定义一个空字典,以便把获取的cookies以字典的形式写入
for items in cookies: #把登录成功后获取的cookies提取name和value参数写入空字典cookie
cookie[items.get('name')] = items.get('value')
with open('cookies.txt','w') as file: #新建并打开一个cookies.txt文件
file.write(json.dumps(cookie)) #写入转成字符串的字典
driver.close() #关闭浏览器4.新建一个py文件,代码如下
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
import requests
import json
import re #正则模块
import random #随机数模块
import time
#query = 'python'
#读取之前登录后保存的cookies
with open('cookies.txt','r') as file:
cookie = file.read()
url = 'https://mp.weixin.qq.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&share=1&token=773059916&lang=zh_CN',
'Host': 'mp.weixin.qq.com',
}
cookies = json.loads(cookie) #加载之前获取的cookies
print(cookies) #可以打印看看,和之前保存的cookies是一样的
response = requests.get(url, cookies = cookies) #请求https://mp.weixin.qq.com/,传cookies参数,登录成功
token = re.findall(r'token=(\d+)',str(response.url))[0] #登录成功后,这是的url里是包含token的,要把token参数拿出来,方便后面构造data数据包发起post请求
#print(token)
#random.random()返回0到1之间随机数
#构造data数据包发起post请求
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': 'python',
'begin': '0',
'count': '3',
}
search_url = 'https://mp.weixin.qq.com/cgi-bin/operate_appmsg?sub=check_appmsg_copyright_stat' #按F12在浏览器里找post请求的url(搜索文章请求的url)
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers) #发起post请求,传cookies、data、headers参数
max_num = search_response.json().get('total') #获取所有文章的条数
num = int(int(max_num/3)) #每页显示3篇文章,要翻total/3页,不过实际上我搜索了几个关键词,发现微信公众号文章搜索的接口最多显示667页,其实后面还有页数,max_num/3的结果大于667没关系
if __name__ == '__main__':
query = input('请输入你要搜索的内容:')
begin = 0
while num +1 > 0:
print(begin)
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': query,
'begin': '{}'.format(str(begin)),
'count': '3',
}
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers)
contentt = search_response.json().get('list') #list里面是我们需要的内容,所以要获取list
for items in contentt: #具体需要list里面的哪些参数可以自己选择,这里只获取title、url、nickname、author
f = open('search.txt',mode='a',) #打开一个txt文档,把获取的内容写进去,mode='a'是追加的方式写入,不覆盖
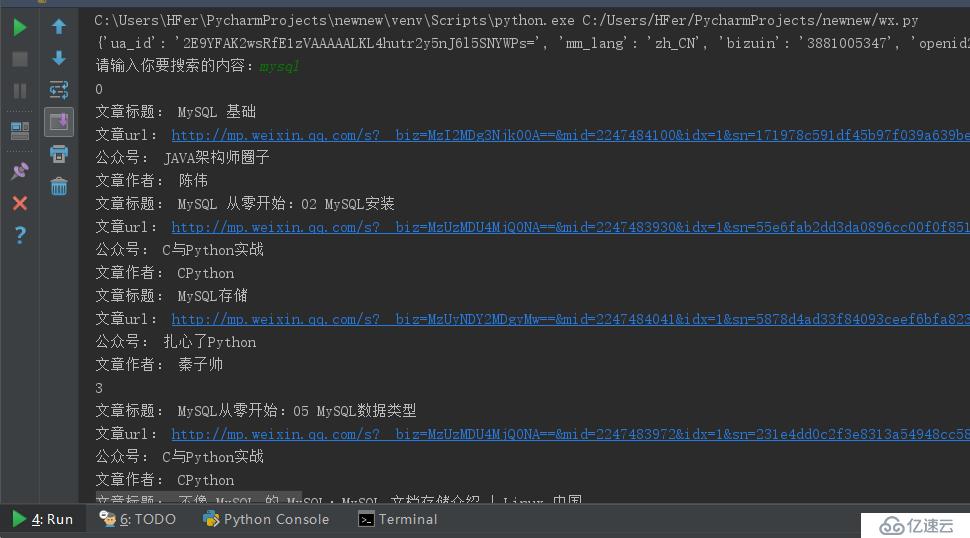
print('文章标题:',items.get('title')) #获取文章标题
f.write('文章标题:')
f.write(items.get('title'))
f.write("\n")
f.write('文章url:')
f.write(items.get('url'))
f.write("\n")
f.write('公众号:')
f.write(items.get('nickname'))
f.write("\n")
f.write('作者:')
f.write(items.get('author'))
f.write("\n")
f.write("\n")
print('文章url:',items.get('url')) #获取文章的url
print('公众号:',items.get('nickname')) #获取出自哪个微信公众号
print('文章作者:',items.get('author')) #获取文章作者
num -= 1
begin = int(begin)
begin += 3
time.sleep(3)- 运行结果如下:
- search.txt里保存的内容如下:

- 只要有一个微信公众号就可以实现,可以注册一个试一试。
下一篇:文件处理器——sed
相关内容
热门资讯
还在点火?特朗普批准,美企或在...
美国《华尔街日报》7月22日报道,据美国官员透露,美国总统特朗普已正式批准与沙特阿拉伯达成一项具有里...
基本建成交通强国将取得决定性进...
新华社北京7月21日电 题:基本建成交通强国将取得决定性进展——国新办发布会聚焦“十五五”时期交通运...
台防务部门呼吁通过所谓无人机条...
7月22日上午,国台办举行例行新闻发布会。记者:据报道,台防务部门负责人近日称,呼吁通过行政部门无人...
英媒:为什么世界更相信中国而不...
当下西方世界深陷信任危机,民众对体制普遍失望愤怒。美国全球公信力持续崩塌,多国对华信任度已反超美国。...
“台青e家”平台上线运行,国台...
7月22日,国务院台办举行例行新闻发布会。有记者问:在海峡两岸青年文化月活动期间,国务院台办主任宋涛...
视频丨从“有学上”到“上好学”...
教育强国,基点在基础教育。我国拥有43万所中小学幼儿园、2.2亿在校生、1577万专任教师,建成了世...
“看到这几张脸生理性厌恶!”你...
近期,“对AI脸感到不适”相关话题接连冲上社交平台热搜。打开短视频平台刷微短剧,连续刷几部后,主角个...
今年上半年全国城镇新增就业69...
今天(22日)上午,人力资源社会保障部举行新闻发布会。今年上半年,全国城镇新增就业695万人,同比持...
委内瑞拉强震遇难人数升至534...
当地时间21日,委内瑞拉全国代表大会主席豪尔赫·罗德里格斯通过社交媒体通报,该国6月24日两次强震造...
高考684分花3000元咨询进...
潮新闻客户端 青年特约评论员 曾耀湘图源:视觉中国近日,据齐鲁晚报报道,河北一名2018级考生,因“...