scrapy简单入门及实例讲解
爬虫是python最常见的一类应用,但是如何自己动手来写一个爬虫,这可能是很多人关心的问题,这次准备用30分钟来教会大家如何自己动手编写一个Scrapy爬虫的应用
推荐一个不错的Scrapy视频教程给大家,可以直接点击观看:https://www.bilibili.com/video/av27042686/
一、理解爬虫原理
首先,我们需要理解爬虫的原理,只是拿一个库来用谁都会,但理解它的原理才对大家有好处
通过上图我们可以对爬虫的工作原理(不仅限于Scrapy框架)有一个认识:
- 数据源:需要知道从哪里拿到你要的数据,可以是Web,也可以是App或其他应用
- 下载器(Download):需要将数据下载到本机才能进行分析工作,而在下载中我们需要关注几件事:性能、模拟操作和分布式等
- 分析器(Parser):对已下载的数据进行分析,有很多种,比如HTML、正则、json等,当然,在分析的过程中,也能发现更多的链接,从而生成更多采集任务
- 数据存储(Storage):可以将数据保存在数据或磁盘上,以供后续产品的调取、分析等
既然理解了爬虫的原理,我们可以更进一步的认识一下Scrapy框架
二、认识Scrapy框架
Scrapy是Python中很成熟、很常用的一个框架,大部分Python爬虫都是由Scrapy来编写的,那么,为了理解Scrapy的基本结构,我们先来看一张图:
其实,这张图和我们之前说的爬虫原理是一一对应的,我们来看看:
- 下载器(Downloader):将数据下载回来,以供分析
- 爬虫(Spider):这个其实是用于分析的(Parser),用于对下载的数据进行分析
- 调度器(Scheduler):负责调度任务
- 数据管道(Pipeline):负责把数据导出给其他程序、文件、数据库
三、认识Scrapy项目
当然,只是了解上述内容其实意义不大,我们来通过动手做一个例子理解Scrapy
1.搭建初识项目环境
在正式开始编写爬虫之前,我们需要先来创建一个项目
$> scrapy startproject 项目名称
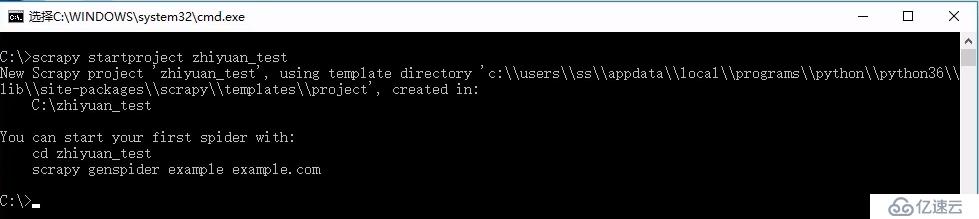
2.认识项目目录
先来了解一下刚刚创建好的目录里面都有什么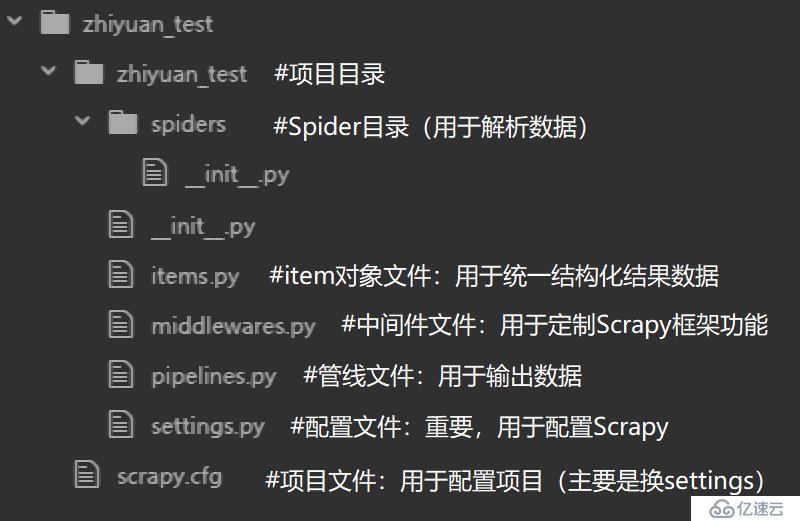
在这里面,其实只有两个东西是我们目前需要关心的:
- spiders目录:编写的所有爬虫类,都会放在这里
- settings.py:Scrapy框架提供的所有设置,都会通过这个文件来修改
3.理解“中间件”和”items”
本文我们先关心最基本的功能,所以不会过于深入Scrapy的细节,所以只对中间件和items的功能做一简单叙述,在其他文章中再详细说明:
- 中间件:由于各类数据源其实有很多差异,所以middlewares用于屏蔽这种差异,以便于统一处理
- items:对项目中所有数据进行统一化,生成统一的结构化数据,从而实现程序(爬虫和其他程序)的标准化
四、抓取案例
本案例中,我们准备抓取一个拍卖手机号的网站:http://www.jihaoba.com/escrow/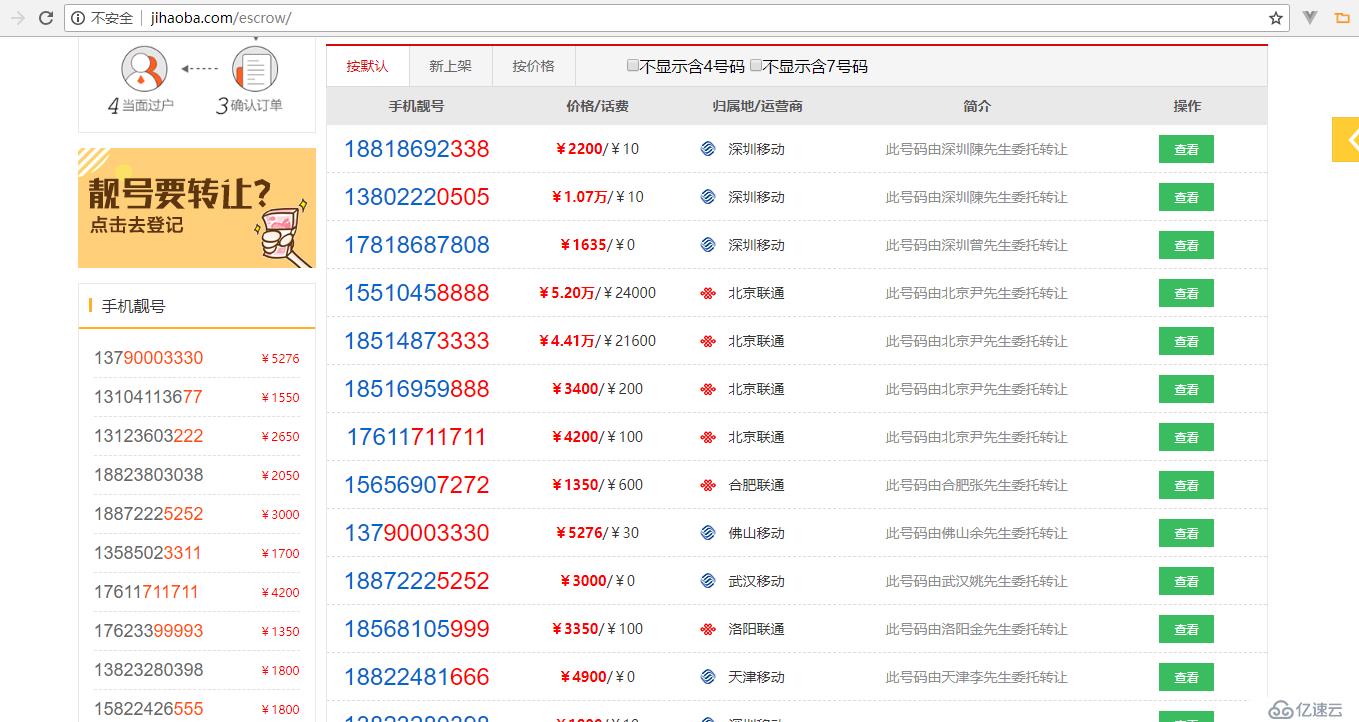
1.创建spider
在刚刚创建好的项目中,我们再创建一个文件:phone_spider.py
2.编写Spider类
import scrapy
class PhoneSpider(scrapy.Spider):
name='phone'
start_urls=[
'http://www.jihaoba.com/escrow/'
]
def parse(self, response):
pass在这里我们主要关心几件事:
- name:spider的名字,用于启动抓取(后面会说)
- start_urls:起始抓取地址,后续任务可能产生更多url,但start_urls是入口
- parse方法:默认的解析回调方法,当下载完成后会自动调用
3.启动抓取
尽管现在还没有实际的工作,但我们可以试着启动爬虫的抓取
scrapy crawl phone

我们可以看到爬虫的抓取能够正常启动
4.为爬虫添加功能
我们可以继续为爬虫加入实际的功能
import scrapy
class PhoneSpider(scrapy.Spider):
name='phone'
start_urls=[
'http://www.jihaoba.com/escrow/'
]
def parse(self, response):
for ul in response.xpath('//div[@class="numbershow"]/ul'):
phone=ul.xpath('li[contains(@class,"number")]/a/@href').re("\\d{11}")[0]
price=ul.xpath('li[@class="price"]/span/text()').extract_first()[1:]
print(phone, price)
这里我们用了一个非常重要的东西——xpath,xpath是一种用于从XML和HTML中提取数据的查询语言,在这里不做赘述,想了解更多xpath的内容请点击https://www.bilibili.com/video/av30320885
再次启动抓取,我们会看到一些有用的数据产生了
5.爬虫数据导出
当然,我们现在只是把print出来,这肯定不行,需要把数据保存到文件中,以便后续使用
所以,将print改为yield
import scrapy
class PhoneSpider(scrapy.Spider):
name='phone'
start_urls=[
'http://www.jihaoba.com/escrow/'
]
def parse(self, response):
for ul in response.xpath('//div[@class="numbershow"]/ul'):
phone=ul.xpath('li[contains(@class,"number")]/a/@href').re("\\d{11}")[0]
price=ul.xpath('li[@class="price"]/span/text()').extract_first()[1:]
#print(phone, price)
yield {
"phone": phone,
"price": price
}
再次运行,并且需要修改运行命令,添加输出选项
scrapy crawl phone
改为
scrapy crawl phone -o data.json
我们可以看到,运行后目录中会多出一个data.json,打开后就是我们要的结果数据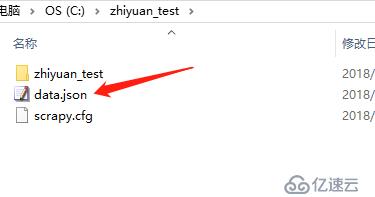
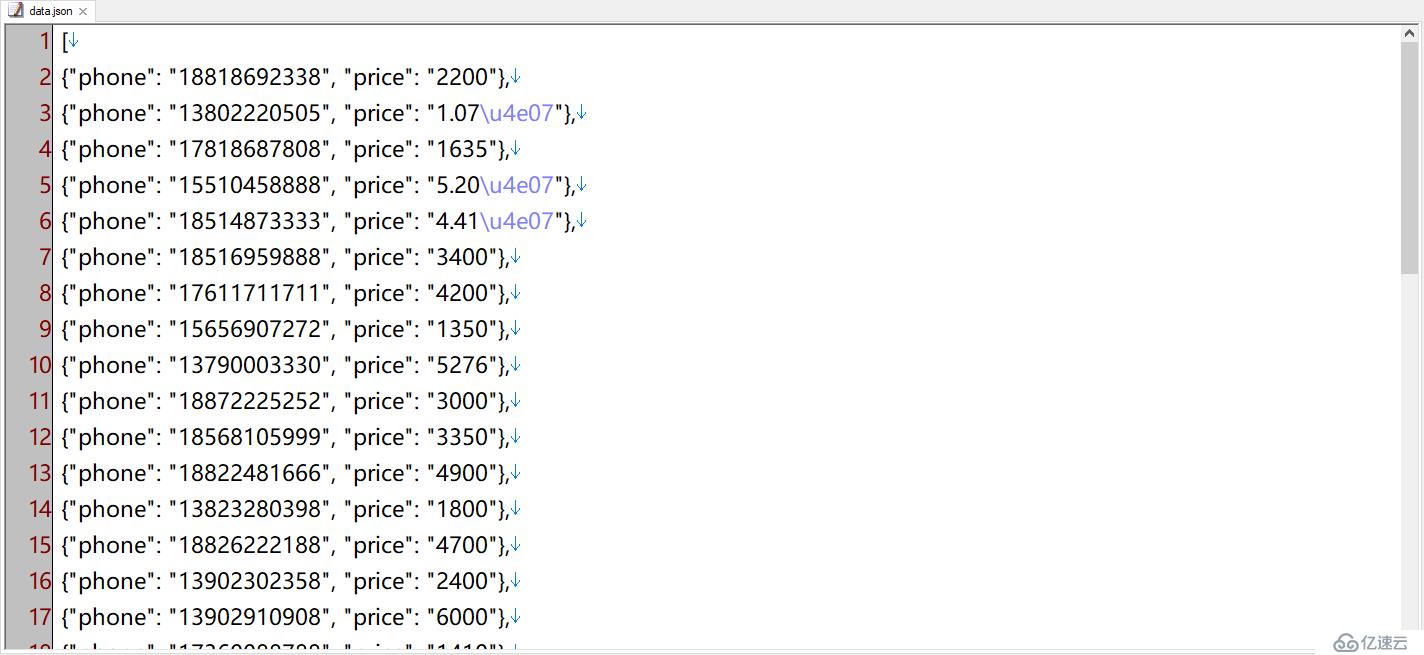
注意,这里导出的价格中,有的带有“\u4e07”,这其实是中文“万”的unicode码,并不影响数据使用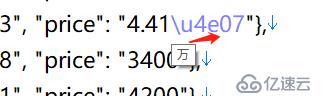
6.抓取更多数据
目前只抓取了第一页的数据,而我们希望能获取所有的数据,所以需要找到下一页的地址,并让爬虫进入其中继续抓取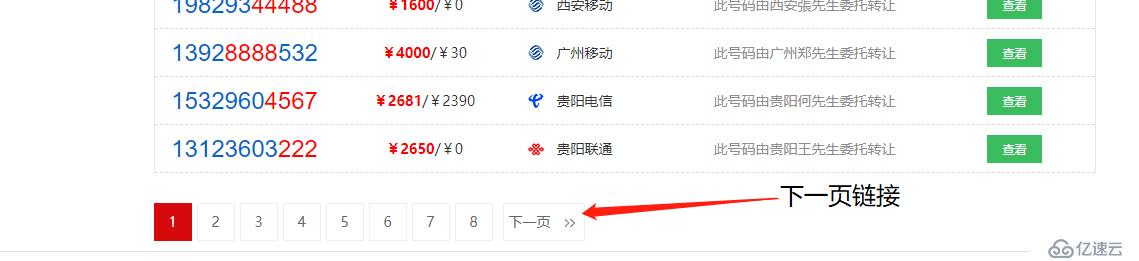
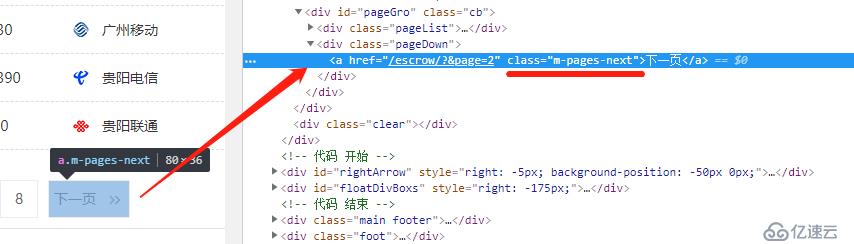
所以,我们需要对代码进行修改
import scrapy
class PhoneSpider(scrapy.Spider):
name='phone'
start_urls=[
'http://www.jihaoba.com/escrow/'
]
def parse(self, response):
for ul in response.xpath('//div[@class="numbershow"]/ul'):
phone=ul.xpath('li[contains(@class,"number")]/a/@href').re("\\d{11}")[0]
price=ul.xpath('li[@class="price"]/span/text()').extract_first()[1:]
#print(phone, price)
yield {
"phone": phone,
"price": price
}
#继续抓取下一页
next="http://www.jihaoba.com"+response.xpath('//a[@class="m-pages-next"]/@href').extract_first()
yield scrapy.Request(next)我们再次启动爬虫
scrapy crawl phone -o data.json
这次,我们会得到比之前多的数据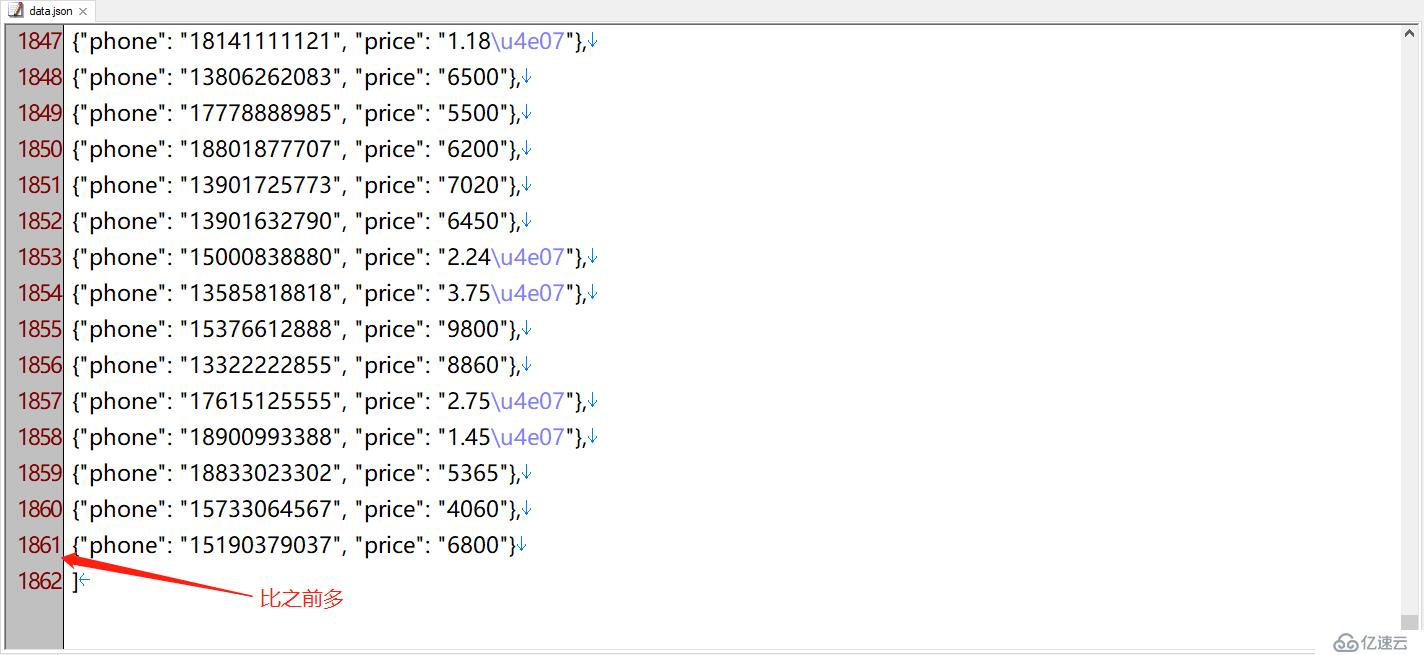
上一篇:Python3 找素数
下一篇:程序功能需要员工即时查看更新