如何通过 Scrapyd + ScrapydWeb 简单高效地部署和监控分布式爬虫项目
admin
2023-07-16 02:21:42
0次
安装和配置
- 请先确保所有主机都已经安装和启动 Scrapyd,如果需要远程访问 Scrapyd,则需将 Scrapyd 配置文件中的 bind_address 修改为
bind_address = 0.0.0.0,然后重启 Scrapyd service。 - 开发主机或任一台主机安装 ScrapydWeb:
pip install scrapydweb - 通过运行命令
scrapydweb启动 ScrapydWeb(首次启动将自动在当前工作目录生成配置文件)。 - 启用 HTTP 基本认证(可选):
ENABLE_AUTH = True USERNAME = 'username' PASSWORD = 'password' - 添加 Scrapyd server,支持字符串和元组两种配置格式,支持添加认证信息和分组/标签:
SCRAPYD_SERVERS = [ '127.0.0.1', # 'username:password@localhost:6801#group', ('username', 'password', 'localhost', '6801', 'group'), ] - 运行命令
scrapydweb重启 ScrapydWeb。
访问 web UI
通过浏览器访问并登录 http://127.0.0.1:5000。
- Servers 页面自动输出所有 Scrapyd server 的运行状态。
- 通过分组和过滤可以自由选择若干台 Scrapyd server,然后在上方 Tabs 标签页中选择 Scrapyd 提供的任一 HTTP JSON API,实现一次操作,批量执行。
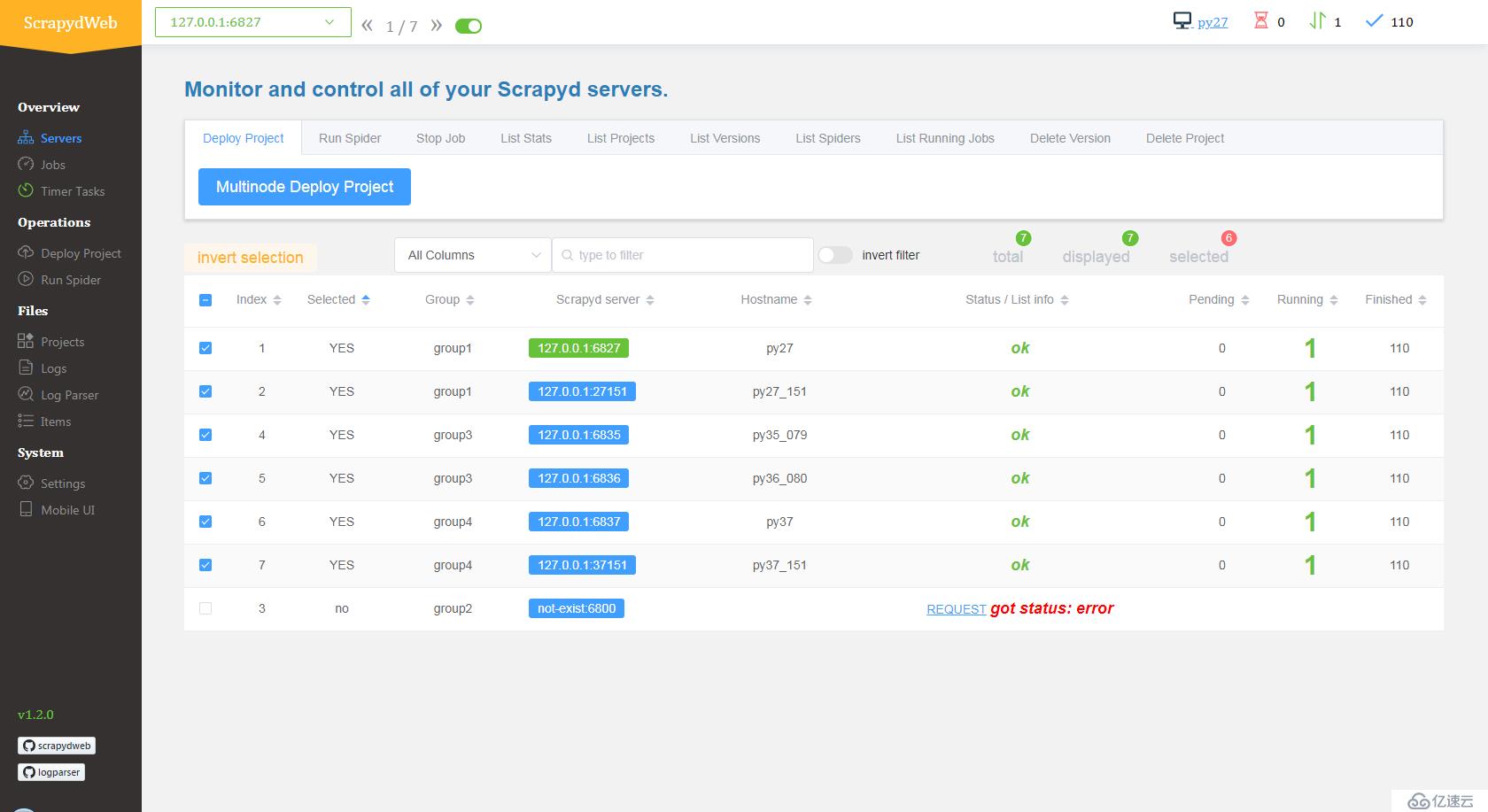
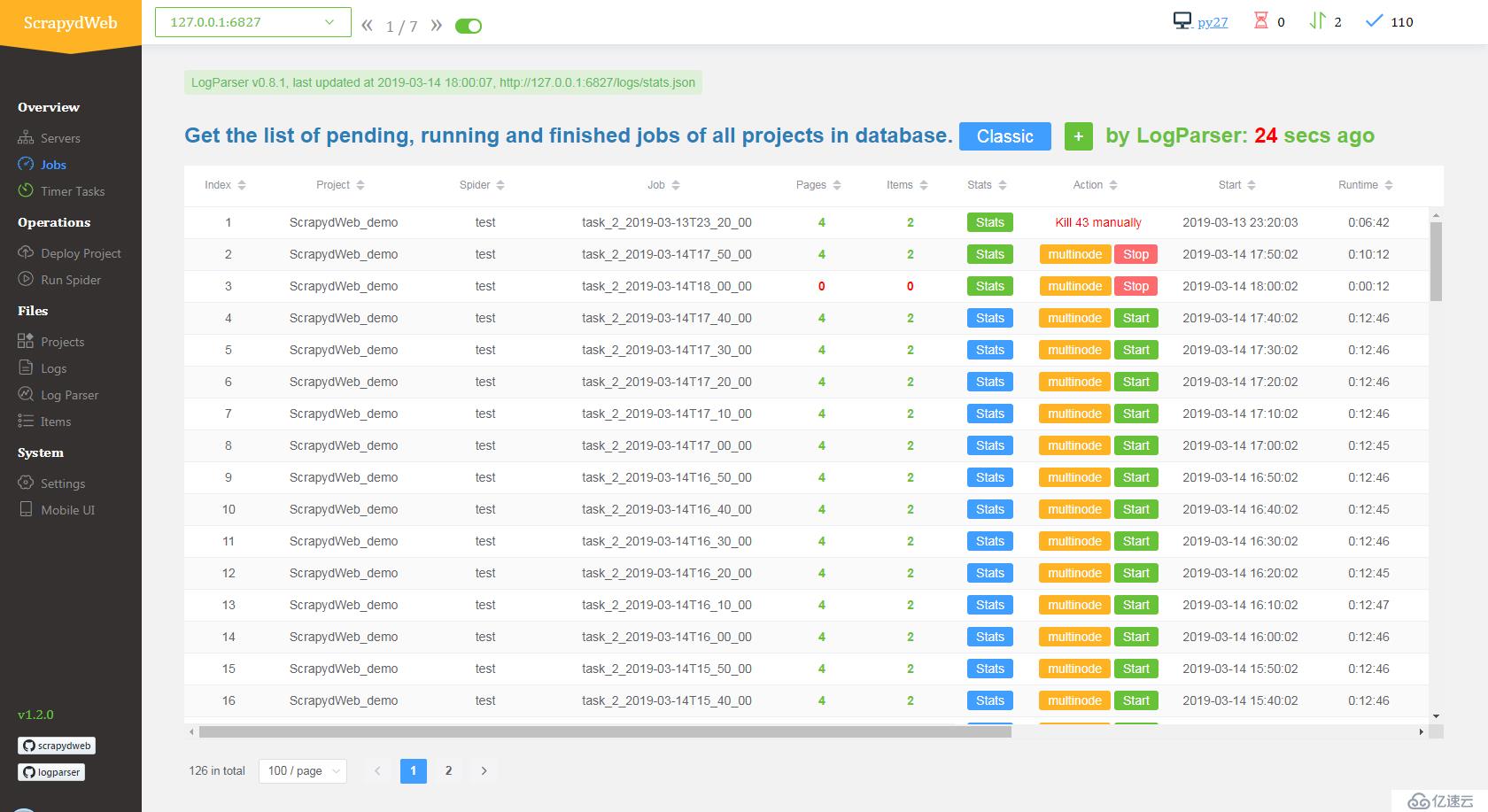
- 通过集成 LogParser,Jobs 页面自动输出爬虫任务的 pages 和 items 数据。
- ScrapydWeb 默认通过定时创建快照将爬虫任务列表信息保存到数据库,即使重启 Scrapyd server 也不会丢失任务信息。(issue 12)
部署项目
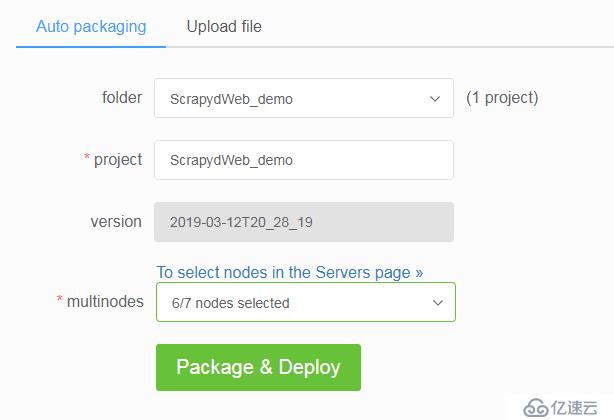
- 通过配置
SCRAPY_PROJECTS_DIR指定 Scrapy 项目开发目录,ScrapydWeb 将自动列出该路径下的所有项目,默认选定最新编辑的项目,选择项目后即可自动打包和部署指定项目。 - 如果 ScrapydWeb 运行在远程服务器上,除了通过当前开发主机上传常规的 egg 文件,也可以将整个项目文件夹添加到 zip/tar/tar.gz 压缩文件后直接上传即可,无需手动打包为 egg 文件。
- 支持一键部署项目到 Scrapyd server 集群。
运行爬虫
- 通过下拉框依次选择 project,version 和 spider。
- 支持传入 Scrapy settings 和 spider arguments。
- 支持创建基于 APScheduler 的定时爬虫任务。(如需同时启动大量爬虫任务,则需调整 Scrapyd 配置文件的 max-proc 参数)
- 支持在 Scrapyd server 集群上一键启动分布式爬虫。
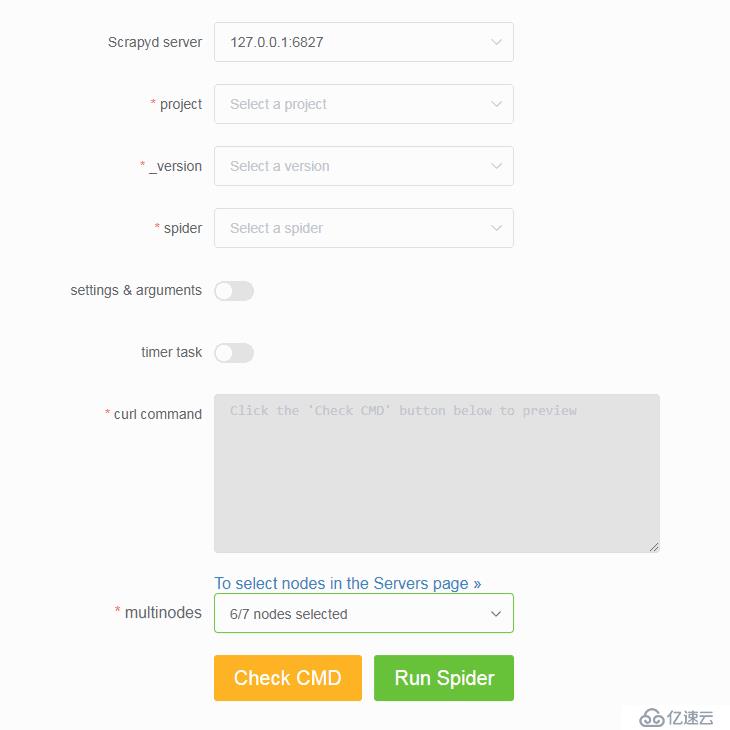
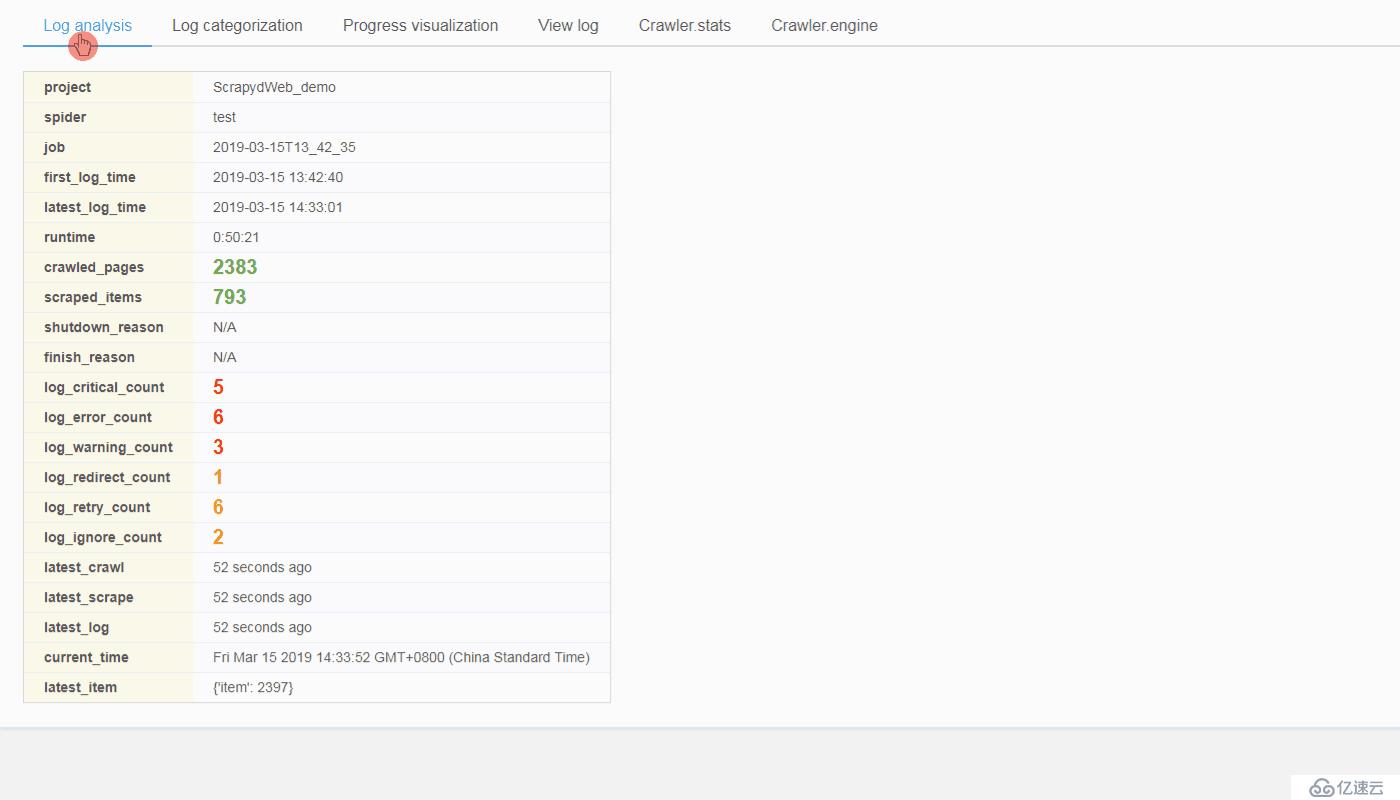
日志分析和可视化
- 如果在同一台主机运行 Scrapyd 和 ScrapydWeb,建议设置
SCRAPYD_LOGS_DIR和ENABLE_LOGPARSER,则启动 ScrapydWeb 时将自动运行 LogParser,该子进程通过定时增量式解析指定目录下的 Scrapy 日志文件以加快 Stats 页面的生成,避免因请求原始日志文件而占用大量内存和网络资源。 - 同理,如果需要管理 Scrapyd server 集群,建议在其余主机单独安装和启动 LogParser。
- 如果安装的 Scrapy 版本不大于 1.5.1,LogParser 将能够自动通过 Scrapy 内建的 Telnet Console 读取 Crawler.stats 和 Crawler.engine 数据,以便掌握 Scrapy 内部运行状态。
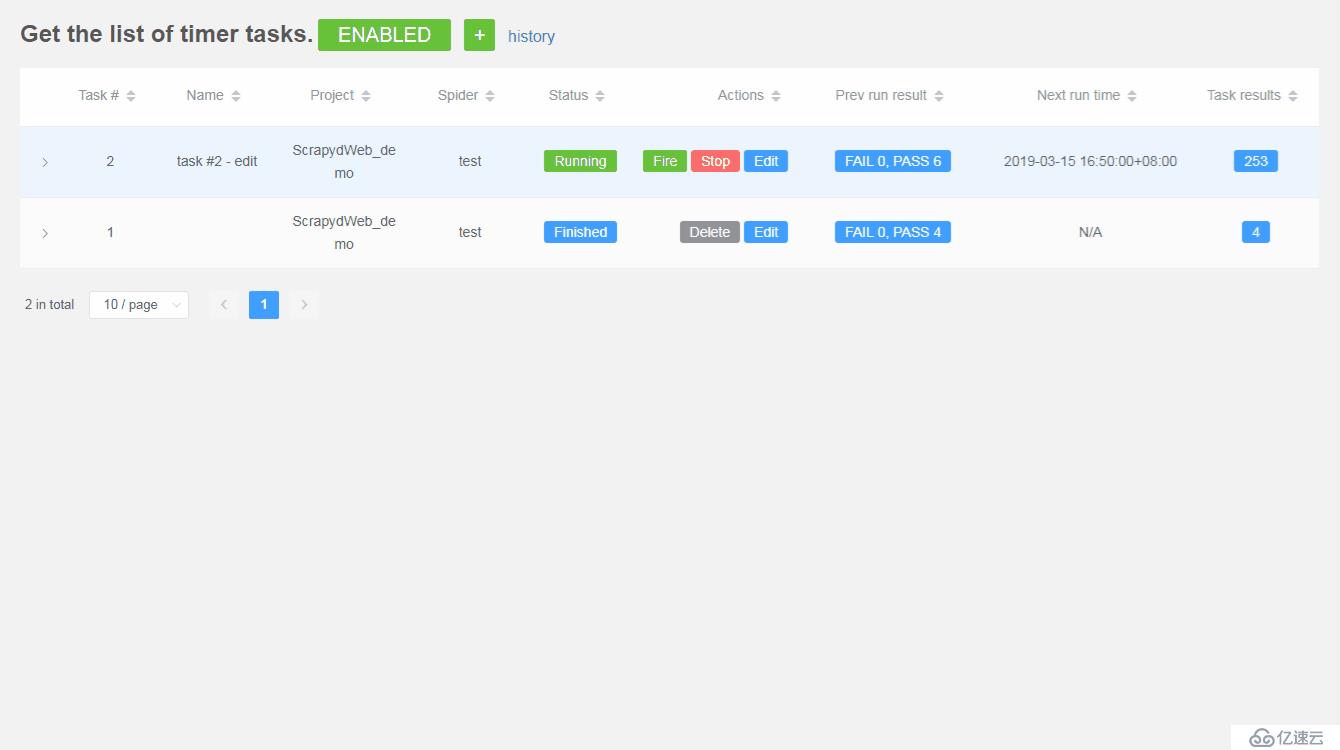
定时爬虫任务
- 支持查看爬虫任务的参数信息,追溯历史记录
- 支持暂停,恢复,触发,停止,编辑和删除任务等操作
邮件通知
通过轮询子进程在后台定时模拟访问 Stats 页面,ScrapydWeb 将在满足特定触发器时根据设定自动停止爬虫任务并发送通知邮件,邮件正文包含当前爬虫任务的统计信息。
- 添加邮箱帐号:
SMTP_SERVER = 'smtp.qq.com' SMTP_PORT = 465 SMTP_OVER_SSL = True SMTP_CONNECTION_TIMEOUT = 10
EMAIL_USERNAME = '' # defaults to FROM_ADDR
EMAIL_PASSWORD = 'password'
FROM_ADDR = 'username@qq.com'
TO_ADDRS = [FROM_ADDR]
2. 设置邮件工作时间和基本触发器,以下示例代表:每隔1小时或当某一任务完成时,并且当前时间是工作日的9点,12点和17点,*ScrapydWeb* 将会发送通知邮件。
```python
EMAIL_WORKING_DAYS = [1, 2, 3, 4, 5]
EMAIL_WORKING_HOURS = [9, 12, 17]
ON_JOB_RUNNING_INTERVAL = 3600
ON_JOB_FINISHED = True- 除了基本触发器,ScrapydWeb 还提供了多种触发器用于处理不同类型的 log,包括 'CRITICAL', 'ERROR', 'WARNING', 'REDIRECT', 'RETRY' 和 'IGNORE'等。
LOG_CRITICAL_THRESHOLD = 3 LOG_CRITICAL_TRIGGER_STOP = True LOG_CRITICAL_TRIGGER_FORCESTOP = False # ... LOG_IGNORE_TRIGGER_FORCESTOP = False以上示例代表:当日志中出现3条或以上的 critical 级别的 log 时,ScrapydWeb 将自动停止当前任务,如果当前时间在邮件工作时间内,则同时发送通知邮件。
移动端 UI
GitHub 开源
my8100/scrapydweb
下一篇:爬取豆瓣的tp250电影名单
相关内容
热门资讯
特朗普:正致力于与伊朗达成协议...
特朗普在《纽约邮报》一档播客访谈节目中称,他正与伊朗磋商一项协议,伊朗已同意不再谋求拥有核武器。他表...
不接壤的日菲为何偷划海界?
日菲近日发表联合声明,宣称就“划定两国专属经济区和大陆架的海洋边界”启动正式谈判。两个隔海相望的国家...
凤凰晚报丨从钳工到老戏骨,魏宗...
今日人物【从钳工到老戏骨,魏宗万用一生诠释“戏比天大”】6月1日,表演艺术家魏宗万在上海逝世,享年8...
科威特称伊朗袭击致63人受伤
科威特卫生部门3日称,伊朗当天对科威特的袭击已造成63人受伤,相关部门已启动紧急应对预案,并在全国范...
日本标榜“和平国家”却行扩军备...
今年是东京审判开庭80周年,世界正回望历史、反思战争罪责、捍卫二战后来之不易的国际秩序之际,日本却迈...
浙江杨梅即将大规模上市,如何破...
“我们现在的压力很大。”5月底,浙江余姚杨梅产区丈亭镇副镇长林宇站在一片杨梅林前对第一财经表示,当地...
致5死2伤!韩国就韩华航空航天...
【环球网报道 记者 姜蔼玲】据韩联社6月1日报道,针对位于韩国大田的韩华航空航天公司发生爆炸致7人伤...
黄河科技学院2026年招生简章
长按图片识别二维码或点击 “阅读原文” 查看电子招生简章。
医路起航,从“心” 开始!黄河...
6月1日上午,黄河科技学院附属医院2022级临床医学本科实习生入院岗前培训在大医讲堂顺利举办。院领导...
问题居然在实体卡槽上!美版iP...
6月2日消息,日前,又有博主提前把还没发布的iPhone 18 Pro电池参数给曝光了出来,根据爆料...