如何免费创建云端爬虫集群
admin
2023-07-10 09:23:58
0次
在线体验
scrapydweb.herokuapp.com
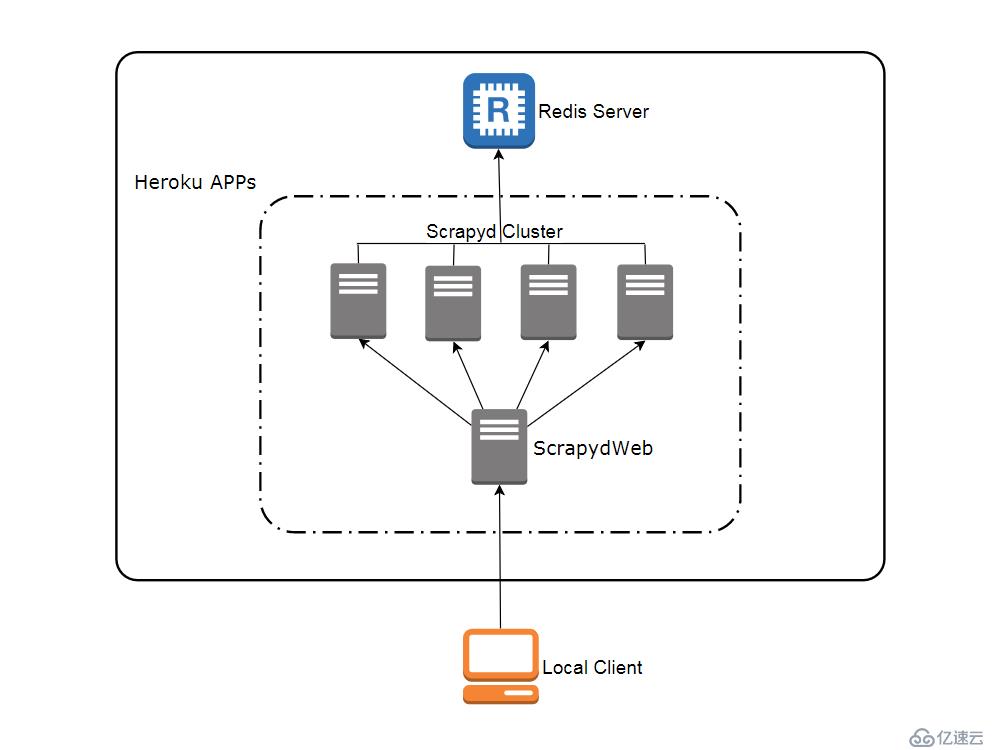
网络拓扑图
注册帐号
- Heroku
访问 heroku.com 注册免费账号(注册页面需要调用 google recaptcha 人机验证,登录页面也需要科学地进行上网,访问 app 运行页面则没有该问题),免费账号最多可以创建和运行5个 app。
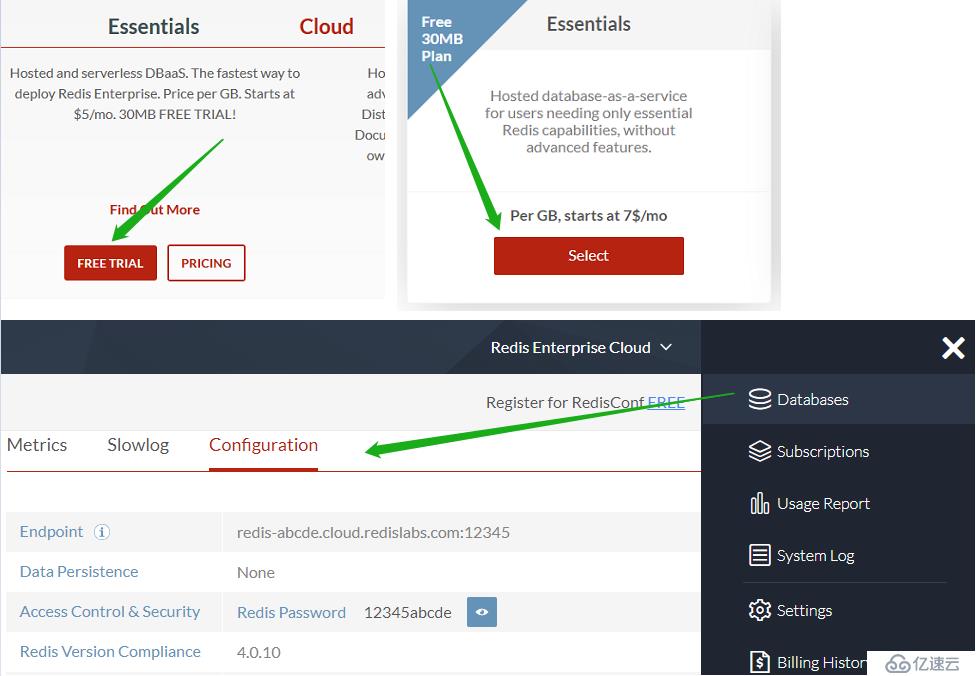
- Redis Labs(可选)
访问 redislabs.com 注册免费账号,提供30MB 存储空间,用于下文通过 scrapy-redis 实现分布式爬虫。
通过浏览器部署 Heroku app
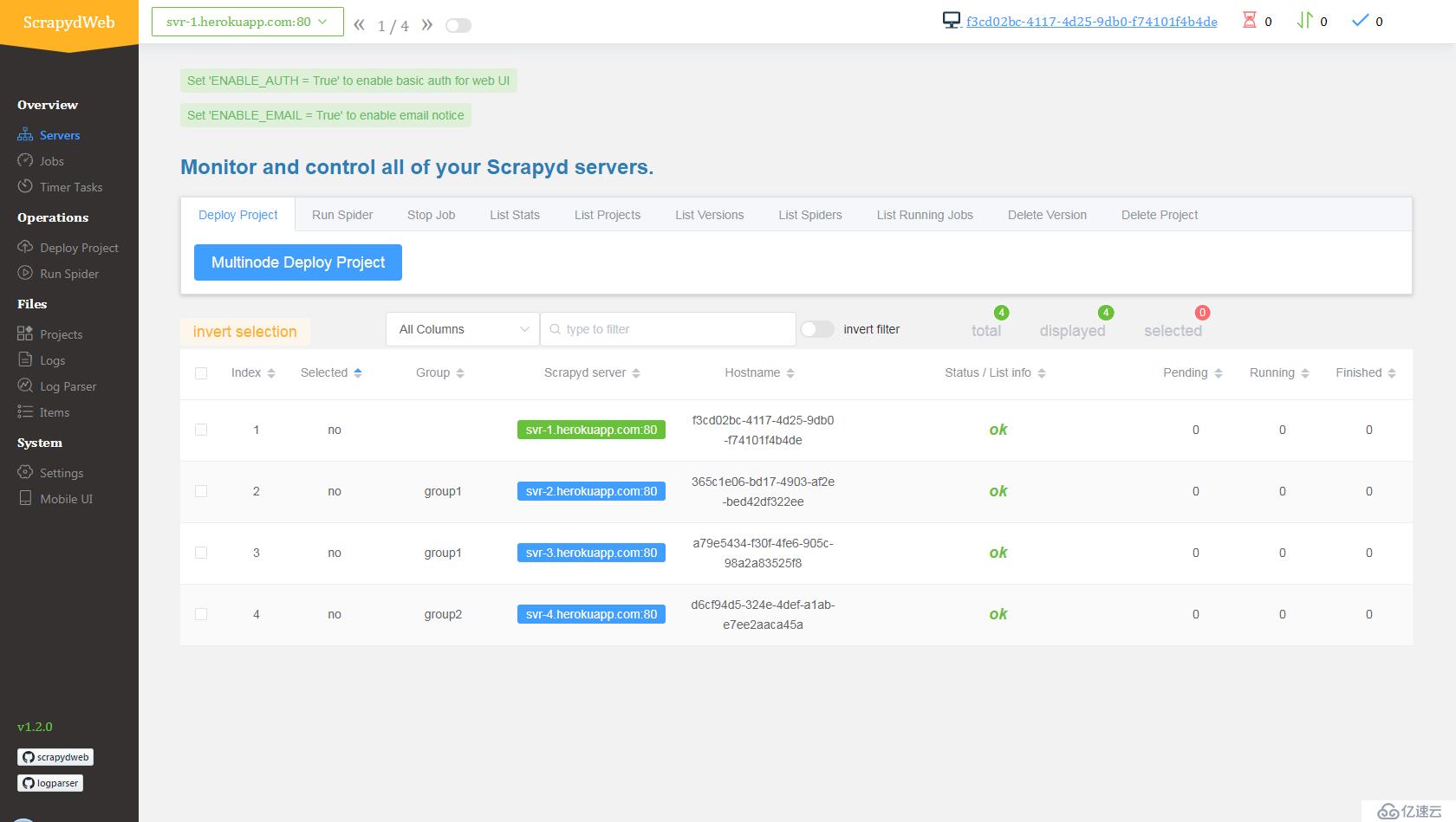
- 访问 my8100/scrapyd-cluster-on-heroku-scrapyd-app 一键部署 Scrapyd app。(注意更新页面表单中 Redis 服务器的主机,端口和密码)
- 重复第1步完成4个 Scrapyd app 的部署,假设应用名称为
svr-1,svr-2,svr-3和svr-4 - 访问 my8100/scrapyd-cluster-on-heroku-scrapydweb-app 一键部署 ScrapydWeb app,取名
myscrapydweb - (可选)点击 dashboard.heroku.com/apps/myscrapydweb/settings 页面中的 Reveal Config Vars 按钮相应添加更多 Scrapyd server,例如 KEY 为
SCRAPYD_SERVER_2, VALUE 为svr-2.herokuapp.com:80#group2 - 访问 myscrapydweb.herokuapp.com
- 跳转 部署和运行分布式爬虫 章节继续阅读。
自定义部署
安装工具
- Git
- Heroku CLI
- Python client for Redis:运行
pip install redis命令即可。
下载配置文件
新开一个命令行提示符:
git clone https://github.com/my8100/scrapyd-cluster-on-heroku
cd scrapyd-cluster-on-heroku登录 Heroku
heroku login
# outputs:
# heroku: Press any key to open up the browser to login or q to exit:
# Opening browser to https://cli-auth.heroku.com/auth/browser/12345-abcde
# Logging in... done
# Logged in as username@gmail.com创建 Scrapyd 集群
-
新建 Git 仓库
cd scrapyd git init # explore and update the files if needed git status git add . git commit -a -m "first commit" git status -
部署 Scrapyd app
heroku apps:create svr-1 heroku git:remote -a svr-1 git remote -v git push heroku master heroku logs --tail # Press ctrl+c to stop logs outputting # Visit https://svr-1.herokuapp.com -
添加环境变量
- 设置时区
# python -c "import tzlocal; print(tzlocal.get_localzone())" heroku config:set TZ=Asia/Shanghai # heroku config:get TZ - 添加 Redis 账号(可选,详见 scrapy_redis_demo_project.zip 中的 settings.py)
heroku config:set REDIS_HOST=your-redis-host heroku config:set REDIS_PORT=your-redis-port heroku config:set REDIS_PASSWORD=your-redis-password
- 设置时区
- 重复上述第2步和第3步完成余下三个 Scrapyd app 的部署和配置:
svr-2,svr-3和svr-4
创建 ScrapydWeb app
-
新建 Git 仓库
cd .. cd scrapydweb git init # explore and update the files if needed git status git add . git commit -a -m "first commit" git status -
部署 ScrapydWeb app
heroku apps:create myscrapydweb heroku git:remote -a myscrapydweb git remote -v git push heroku master -
添加环境变量
- 设置时区
heroku config:set TZ=Asia/Shanghai - 添加 Scrapyd server(详见 scrapydweb 目录下的 scrapydweb_settings_v8.py)
heroku config:set SCRAPYD_SERVER_1=svr-1.herokuapp.com:80 heroku config:set SCRAPYD_SERVER_2=svr-2.herokuapp.com:80#group1 heroku config:set SCRAPYD_SERVER_3=svr-3.herokuapp.com:80#group1 heroku config:set SCRAPYD_SERVER_4=svr-4.herokuapp.com:80#group2
- 设置时区
- 访问 myscrapydweb.herokuapp.com
部署和运行分布式爬虫
- 上传 demo 项目,即 scrapyd-cluster-on-heroku 目录下的压缩文档 scrapy_redis_demo_project.zip
- 将种子请求推入
mycrawler:start_urls触发爬虫并查看结果
In [1]: import redis # pip install redis
In [2]: r = redis.Redis(host='your-redis-host', port=your-redis-port, password='your-redis-password')
In [3]: r.delete('mycrawler_redis:requests', 'mycrawler_redis:dupefilter', 'mycrawler_redis:items')
Out[3]: 0
In [4]: r.lpush('mycrawler:start_urls', 'http://books.toscrape.com', 'http://quotes.toscrape.com')
Out[4]: 2
# wait for a minute
In [5]: r.lrange('mycrawler_redis:items', 0, 1)
Out[5]:
[b'{"url": "http://quotes.toscrape.com/", "title": "Quotes to Scrape", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}',
b'{"url": "http://books.toscrape.com/index.html", "title": "All products | Books to Scrape - Sandbox", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}']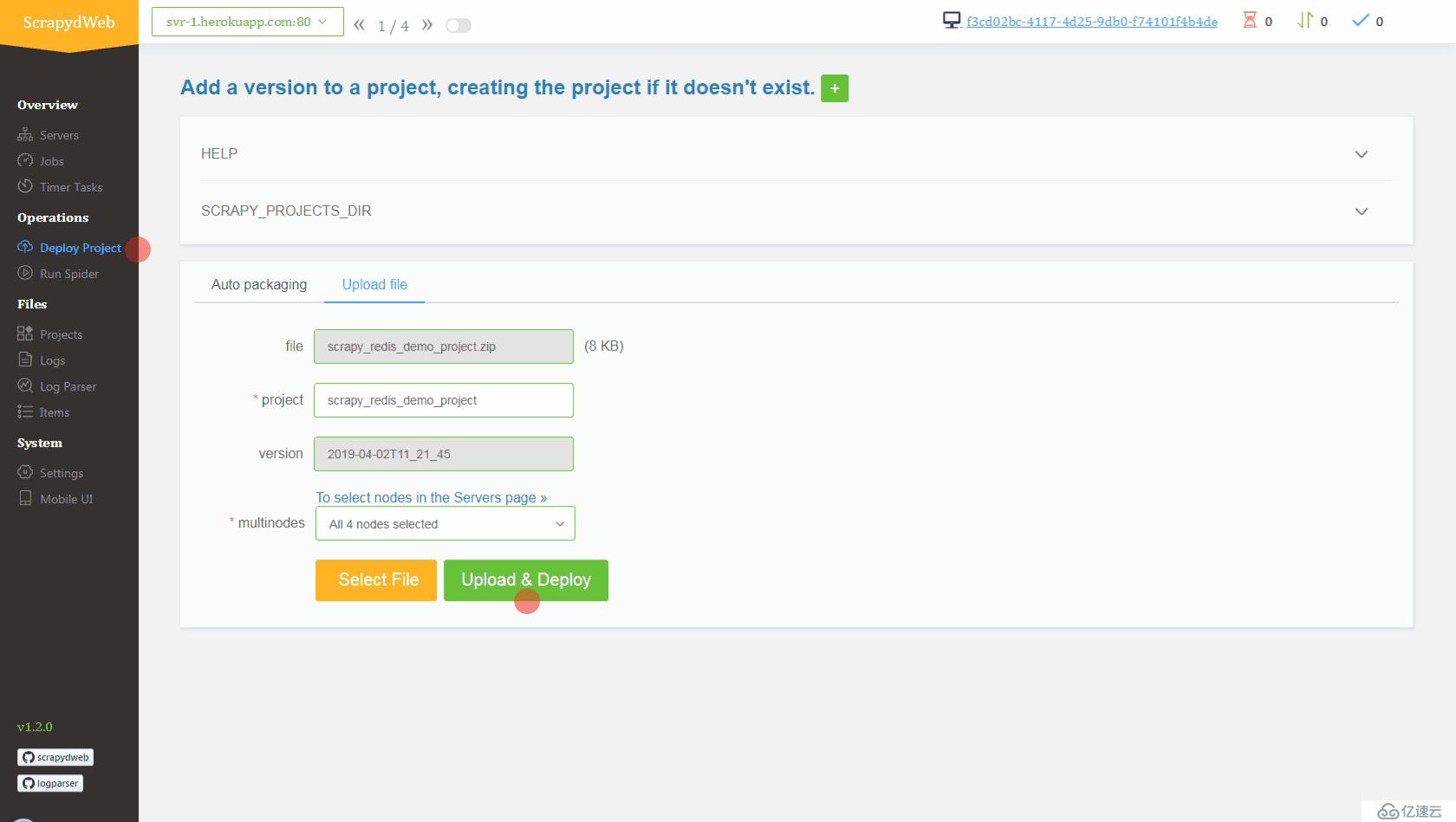
总结
- 优点
- 免费
- 可以爬 Google 等外网
- 可扩展(借助于 ScrapydWeb)
- 缺点
- 注册和登录需要科学地进行上网
- Heroku app 每天至少自动重启一次并且重置所有文件,因此需要外接数据库保存数据,详见 devcenter.heroku.com
GitHub 开源
my8100/scrapyd-cluster-on-heroku
相关内容
热门资讯
美伊谈判濒临破裂之际,伊朗议长...
因为以色列持续对黎巴嫩进行军事打击,伊朗宣布暂停同美国的谈判。不过美国总统特朗普称,对话仍在继续。谈...
罕见!以军政策发生“重大转变”
新华社北京6月1日电 题:罕见纵深推进,以军对黎行动会否搅动美伊谈判新华社记者刘品然 阚静文 席玥以...
山西太原发现一处新石器遗址,出...
山西省太原市文物保护研究院协同相关科研机构,近期在太原市阳曲县西盘威村发现一处新石器时代重要遗址——...
伊媒发布穆杰塔巴罕见照片
伊朗塔斯尼姆通讯社6月1日发布了一张最高领袖穆杰塔巴的照片。照片中,穆杰塔巴面露笑容,抱着一个婴儿。...
福建“泡药杨梅”曝光后,浙江杨...
这两天,浙江本地杨梅少量进入市场。虽然受到此前福建 “泡药杨梅” 事件影响,市场整体销量相比去年同期...
尺素金声 | 前4月规上工业企...
5月27日,国家统计局发布最新数据显示,今年前4月,全国规上工业企业实现利润同比增长18.2%,增速...
郑丽文:台湾民众越来越了解“台...
针对台湾《联合报》民调显示,63%受访者民意希望维持现状,即将访美的中国国民党主席郑丽文1日表示,民...
美前副总统:共和党失去了方向,...
2026年是美国的中期选举年,共和党选情不利,可能在年底的选举中遭遇挫败。美国前副总统彭斯5月31日...
南枝原来去过中国?《给阿嬷的情...
《给阿嬷的情书》票房口碑双丰收,目前票房已突破13亿。凤凰卫视最新一期《问答神州》专访了该片导演蓝鸿...
法国海军扣押一艘俄“影子舰队”...
近日,法国海军在大西洋海域扣押了一艘据称从俄罗斯摩尔曼斯克出发的油轮,引发俄方强烈不满。俄新社6月1...